
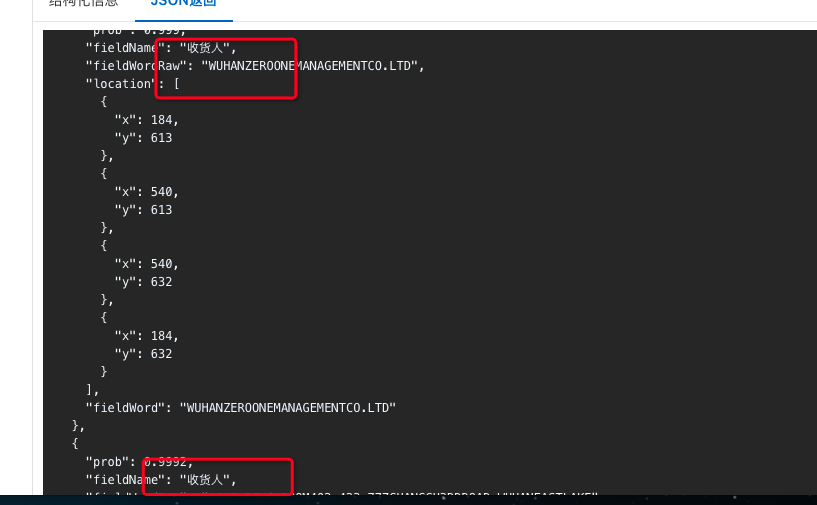
文字识别OCR这里为什么不是一条数据二十每一行一条数据?题目都是一样的,以前是一条数据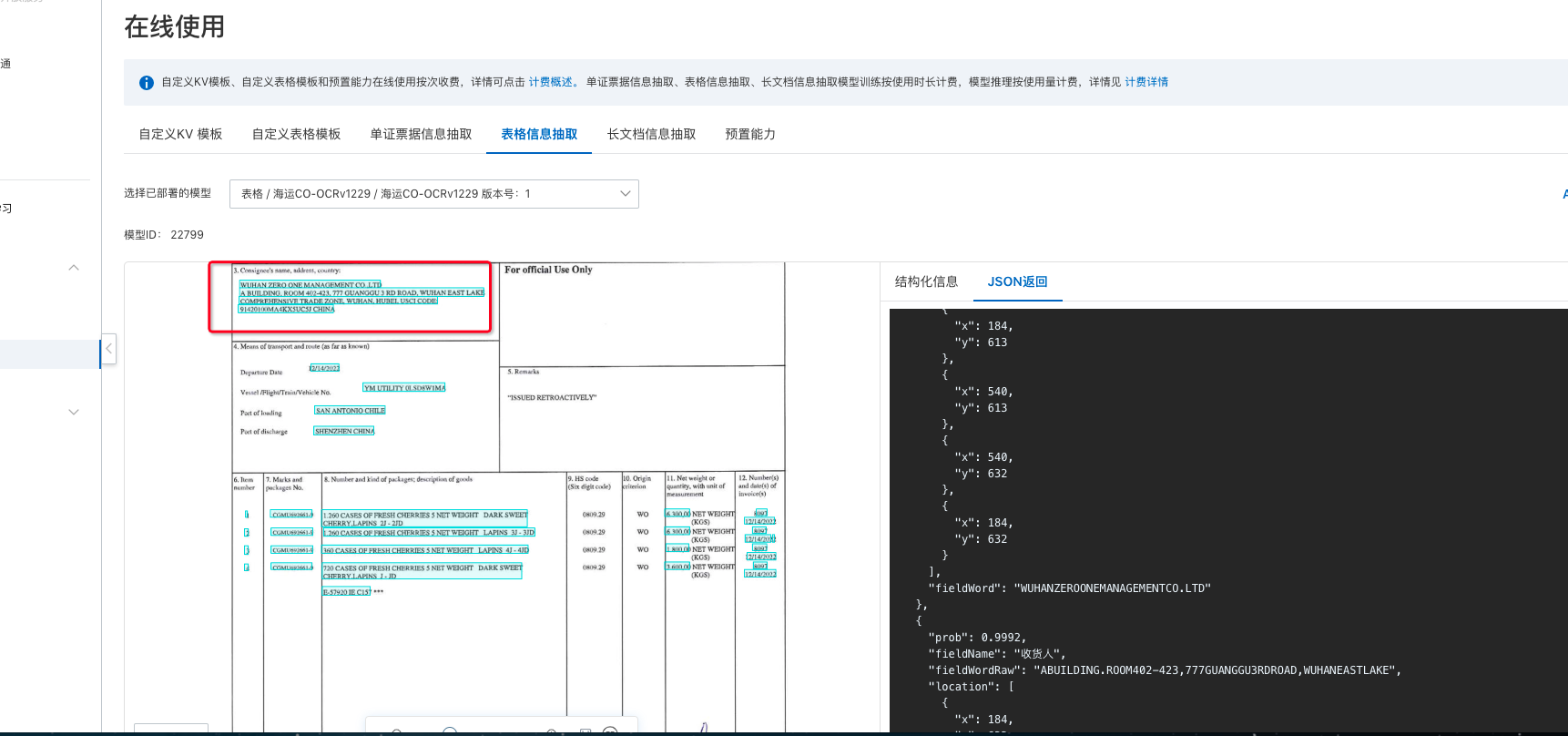
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
文字识别OCR(Optical Character Recognition)是一种将图像中的文字转换为可编辑文本的技术。在处理包含多行文字的图像时,通常会按照每一行生成一条数据的方式进行处理。
这样做的原因有以下几点:
语义理解:每行文字通常代表一个完整的句子或段落,将其作为一条数据进行处理可以更好地保留原文的语义信息。如果将多行文字合并为一条数据,可能会导致语义信息的丢失或混淆。
文本处理:对于包含多行文字的图像,每行文字可能需要进行不同的后续处理操作,例如分词、命名实体识别等。将每行文字作为一条数据进行处理可以更方便地进行这些操作。
错误纠正:在文字识别过程中,可能会出现误识别的情况。将每行文字作为一条数据进行处理可以提高错误纠正的准确性和灵活性。如果将多行文字合并为一条数据,可能会增加错误纠正的难度。


