
用的自训练模型,非常用领域的。只需要识别单个人的讲课内容。在软件上做测试对比,同样一段话实时语音识别效果比录音文件识别效果正确率低很多,这是为什么呢?
录音文件识别的效果也不够理想。希望达到的效果进一步提升,需要做声学模型训练么,怎么操作呢,目前有10个小时左右的音频数据。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
实时语音识别和录音文件识别在效果上存在差异,可能的原因有以下几个方面:
为了进一步提升识别效果,特别是针对特定人的讲课内容,您可以考虑以下操作:
具体操作步骤会涉及大量的数据预处理、模型搭建、训练以及参数调优等工作,建议结合具体的开发平台和技术栈详细查阅相关文档和技术指南。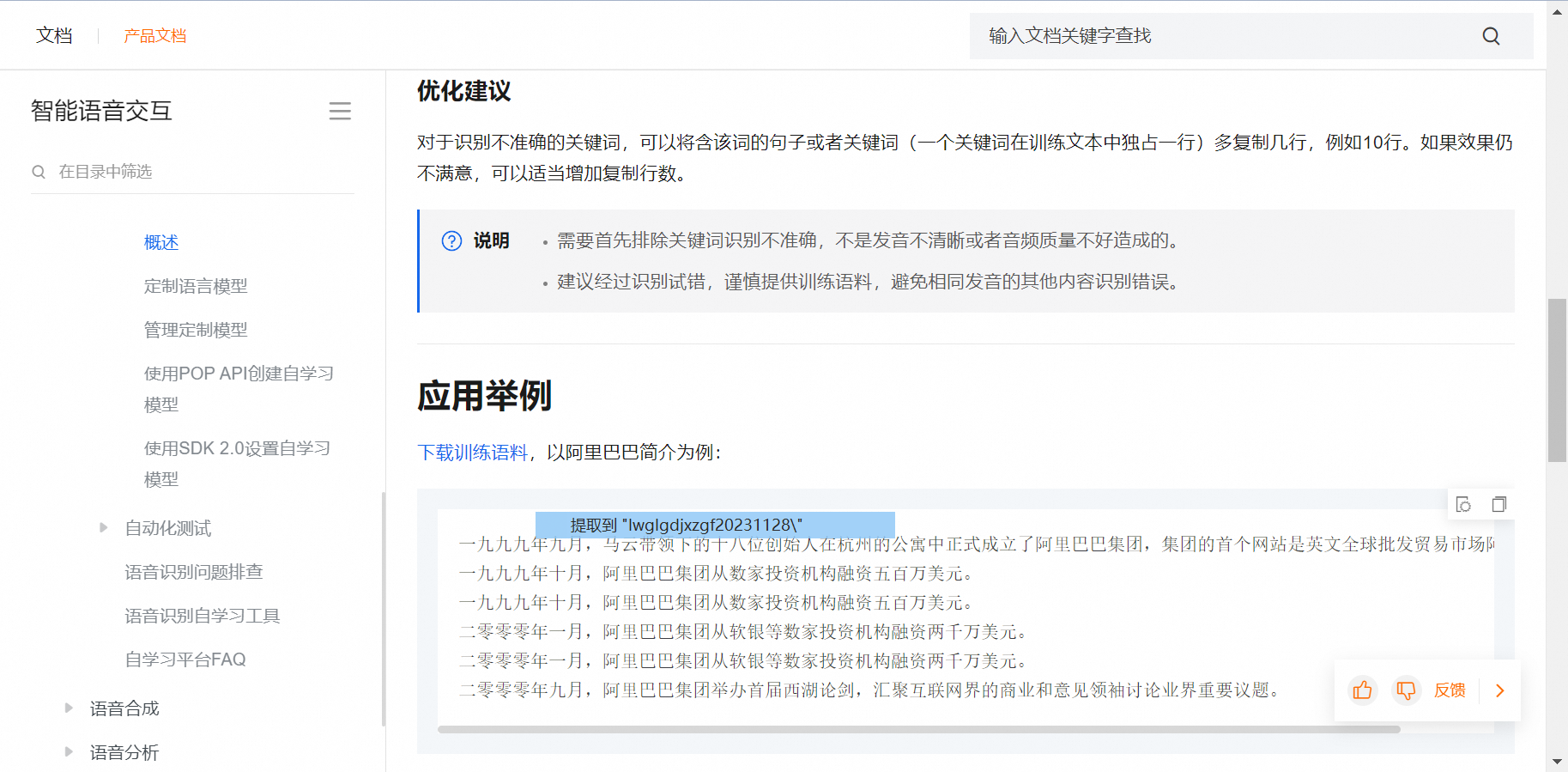
实时语音识别与录音文件识别效果存在差异的原因可能包括以下几点:
噪声干扰:实时识别时,环境中的噪声、回声、混响等干扰因素往往比录音文件更多,这些都会降低识别准确率。
传输质量:实时音频数据在采集和传输过程中可能会出现丢包、压缩失真等问题,而录音文件则是完整无损的,因此识别效果更好。
说话人的发音变化:实时讲话中可能存在语速变化、语气变化、口齿不清等情况,而录音文件相对稳定,对于自训练模型来说更容易适应固定的发音特点。
处理延迟与缓冲:实时系统为了保证交互体验,通常需要设置较短的缓冲区,这可能导致部分语音信号来不及充分分析就被处理,降低了识别精度。
针对您提到的非通用领域的单个人讲课内容的识别优化,以及已有10小时左右的音频数据,可以尝试以下操作来提升识别效果:
数据增强:利用现有数据进行数据增强,模拟各种实际场景下的噪声环境和说话条件,以提高模型的泛化能力。
声学模型训练:基于您的领域特定数据,重新训练或微调声学模型。首先,确保对原始音频进行预处理,如分帧、加窗、提取MFCC特征等;其次,使用深度学习框架(如Kaldi、TensorFlow/TensorFlow Lite for ASR、ESPnet等)搭建并训练声学模型,通过迭代优化使得模型能够更好地匹配讲师的发音特点和专业术语。
语言模型训练:除了声学模型外,定制化语言模型也非常重要,尤其是对于讲课内容这种具有较强领域特性的语言风格,应当用领域相关的文本资料来训练语言模型。
模型融合与解码策略:考虑采用多个模型融合或者更先进的解码算法,比如Lattice rescoring,WFST等,来进一步提升识别结果的质量。
持续收集和标注新数据:如果可能的话,不断收集更多的授课音频,并进行人工校对标注,用于持续迭代和优化模型。
总之,优化智能语音识别的效果是一个涉及数据集准备、模型选择与训练、后处理等多个环节的过程,需要根据实际情况细致调整。
对于识别不准的词该如何进行优化?https://help.aliyun.com/document_detail/316816.html?spm=a2c4g.119258.0.i1
首先考虑无标注优化:
使用业务相关语料进行定制语言模型优化。业务语料包括业务关键词、业务相关的句子和篇章等。训练语料中要尽可能的对词进行泛化。(比如把“银税e贷是什么”、“如何办理银税e贷”等等相关话术加入到训练语料中)
针对依然识别不好的业务关键词,再以复制多行或者提高模型权重的方式进行定制语言模型加强。
个别解决不好的业务关键词,使用泛热词进行优化。
其次考虑有标注优化:
如果主要是因为口音等问题导致的整体识别效果不好,并且无标注优化方式无法解决到满意程度,可以开始声学模型优化。
声学模型优化需要标注数据,标注本身也可以加入业务相关语料中进行语言模型优化。
智能语音交互的识别效果可以通过以下几个方面进行优化:
数据预处理:对录音文件进行降噪、去除静音段等处理,以提高语音信号的质量。
特征提取:选择合适的语音特征提取方法,如MFCC(Mel频率倒谱系数)、PLP(Perceptual Linear Prediction)等,以提取更有效的语音特征。
模型选择与训练:根据你的需求,可以选择适合的语音识别模型,如基于深度学习的RNN(循环神经网络)、LSTM(长短时记忆网络)等。使用你的10个小时左右的音频数据进行模型训练,可以使用开源的语音识别工具包,如Kaldi、DeepSpeech等。
语言模型:为了提高识别准确率,可以添加语言模型,如N-gram模型、Transformer模型等。语言模型可以帮助系统更好地理解上下文信息,从而提高识别效果。
实时识别优化:针对实时语音识别效果比录音文件识别效果正确率低的问题,可以尝试以下方法:
评估与调优:在实际应用中,需要不断评估识别效果,根据评估结果进行模型调优。可以尝试调整模型参数、特征提取方法等,以提高识别准确率。

