
Flink CDC有没有类似canal的实例?【就是在实例里配置监控哪些库,哪些表,包括黑名单,白名单】
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
flink cdc source 的入参,你可以去看看,应该可以是个list ,正则不确定能用,你可以去看看 源码的参数,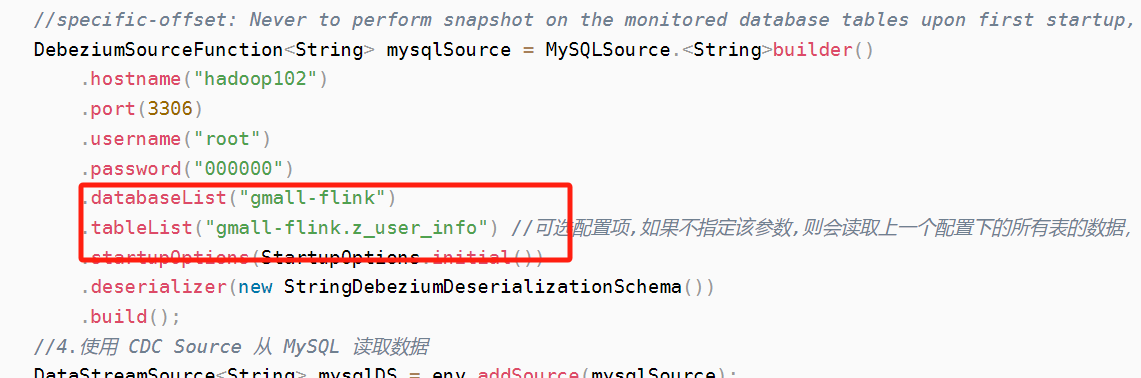
这是个list,传数组的,.databaseList("yourDatabaseName") // set captured database, If you need to synchronize the whole database, Please set tableList to ".*".在过滤一下你要的数据库 ,此回答整理自钉群“Flink CDC 社区”
可以用的元数据如下: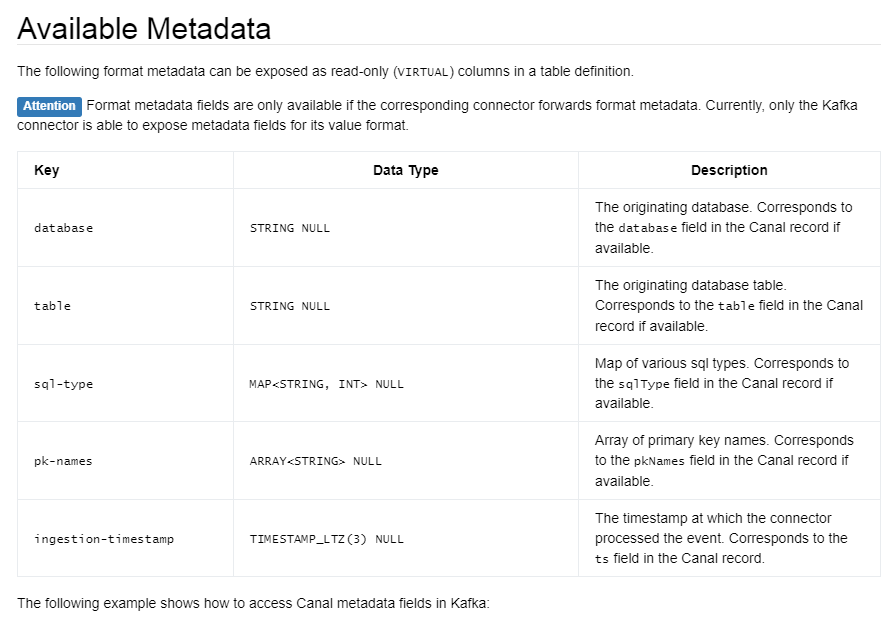
例子:
CREATE TABLE KafkaTable (
origin_database STRING METADATA FROM 'value.database' VIRTUAL,
origin_table STRING METADATA FROM 'value.table' VIRTUAL,
origin_sql_type MAP<STRING, INT> METADATA FROM 'value.sql-type' VIRTUAL,
origin_pk_names ARRAY<STRING> METADATA FROM 'value.pk-names' VIRTUAL,
origin_ts TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL,
user_id BIGINT,
item_id BIGINT,
behavior STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'value.format' = 'canal-json'
);
——参考来源于Flink官方文档。
是的,Flink CDC有一个类似于Canal的实例,叫做Debezium。Debezium是一个开源的分布式流处理框架,它可以与MySQL、PostgreSQL等数据库进行实时数据同步。在Debezium中,你可以配置监控哪些库、哪些表,包括黑名单和白名单。
要使用Debezium,你需要按照以下步骤操作:
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-connector-mysql</artifactId>
<version>1.7.2.Final</version>
</dependency>
import io.debezium.config.Configuration;
import io.debezium.relational.TableId;
import java.util.HashMap;
import java.util.Map;
public class DebeziumMySqlConfig {
public static Configuration config() {
Map<String, String> properties = new HashMap<>();
properties.put("name", "inventory");
properties.put("database.hostname", "localhost");
properties.put("database.port", "3306");
properties.put("database.user", "root");
properties.put("database.password", "password");
properties.put("database.server.id", "184054");
properties.put("database.server.name", "dbserver1");
properties.put("include.schema.changes", "true");
properties.put("table.include.list", "inventory.orders");
properties.put("table.blacklist", "inventory.customers");
properties.put("table.whitelist", "inventory.products");
return Configuration.create(properties);
}
}
在这个例子中,我们监控名为"inventory"的库,只包含名为"orders"的表,同时排除名为"customers"的表,只包含名为"products"的表。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.serialization.SimpleStringSchema;
import org.apache.flink.streaming.util.serialization.JSONKeyValueSerializationSchema;
import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema;
import io.debezium.connector.mysql.MySqlConnector;
import io.debezium.connector.mysql.MySqlConnectionFactory;
import io.debezium.relational.TableId;
import io.debezium.schema.SchemaChangeEvent;
import java.util.Properties;
public class FlinkDebeziumMySqlExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("group.id", "flink-debezium-mysql-example");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"inventory-changes",
new SimpleStringSchema(),
properties);
env.addSource(kafkaConsumer)
.map(new JSONKeyValueSerializationSchema())
.keyBy((KeyedSerializationSchema.SerializationSchema<SchemaChangeEvent<TableId, ?>>) event -> event.key().toJson())
.process(new MySqlProcessor());
env.execute("Flink Debezium MySQL Example");
}
}
在这个例子中,我们使用Debezium连接器从Kafka中消费MySQL的数据变化事件,并将其传递给自定义的MySqlProcessor进行处理。
Flink CDC 没有类似 Canal 的实例,但是可以通过 Flink CDC 的 Source Function 和 Sink Function 来实现自定义的数据同步逻辑。
具体来说,你可以编写一个自定义的 Source Function,用于从指定的数据库中读取数据变更信息,并将其转换为 Flink 数据流。然后,你可以编写一个自定义的 Sink Function,用于将数据流写入到指定的存储系统中。在这两个函数中,你可以根据需要配置监控哪些库、哪些表以及黑名单、白名单等信息。
需要注意的是,自定义的 Source Function 和 Sink Function 需要满足一定的接口规范,并且需要进行相应的测试和验证,以确保其稳定性和可靠性。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


