
Flink CDC有见这个报错不?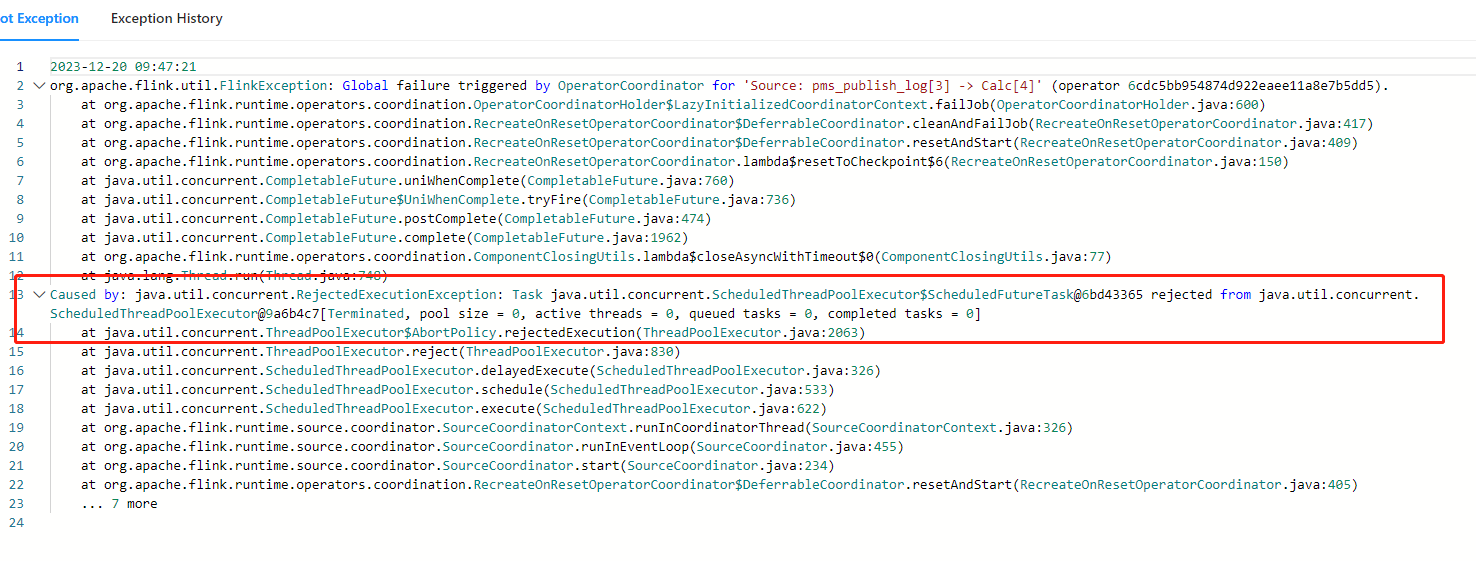
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的错误消息,看起来像是Flink Job出现了全局故障,并触发了 Operator Coordinator 的重置。然后,Job被标记为已停止(Global failure triggered by OperatorCoordinator for 'Source:pms_publish_log[3] -> Calc[4]')。
此外,还有一个未捕获的 RejectedExecutionException 异常,表示 Java.util.concurrent.ScheduledThreadPoolExecutor 已拒绝来自 java.util.concurrent.ScheduledFutureTask@6bd433e7的任务。这意味着当前的工作队列已经满了,所以新添加的任务不能立即开始执行。
要解决这个问题,请按照以下一般性的指导原则进行操作:
监视工作流 - 监视Flink作业的状态以识别任何潜在的性能瓶颈。这可能涉及到检查作业状态页面,观察作业进度条的变化,以及检查作业日志输出。
如果发现CPU利用率过高,可以考虑减少计算密集型转换的数量,或者重新组织数据流动路径以降低复杂度。
如果发现IO等待时间过长,可以评估数据存储系统是否满足需求,或者考虑采用其他技术改进I/O效率。
如果发现内存占用过大,可以考虑增大容器大小,或者优化数据处理过程以减少内存消耗。
调试代码 - 查看相关代码段,特别是那些可能导致过度消费资源的部分。确保它们具有适当的容错性和恢复能力。
优化资源配置 - 只需适当调整Flink作业所需的资源即可缓解压力。这可能意味着增加可用内存量,扩大容器规模,或者选择更适合现有工作负载的机器学习模型。
实施水平伸缩 - 如果有必要,可以部署额外的节点以分摊流量负担。请注意,这种方法仅适用于基于云的服务提供商,其中提供了按需付费的能力。
定期维护 - 定期清理不再使用的临时目录,删除历史记录,释放资源以便后续作业可以高效利用。
这个错误信息来自于Java的ScheduledThreadPoolExecutor类,具体的原因是RejectedExecutionException,也就是任务被拒绝执行。
这个错误通常发生在以下两种情况之一:
对于你的问题,我建议你检查以下几点:
确认你的Flink CDC任务是否在正确的环境中运行。例如,如果你的任务在一个已经被关闭的Flink集群上运行,那么这个错误就可能发生。
检查你的Flink集群的配置。例如,你可以检查你的Flink集群的线程池大小,以及任务的并行度设置。如果线程池的大小太小,或者任务的并行度设置得太高,都可能导致这个错误。
如果可能的话,尝试增加你的Flink集群的线程池大小,或者降低你的任务的并行度设置。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


