
有人用过Flink CDC连接hive吗?我这样插入数据咋不行呢?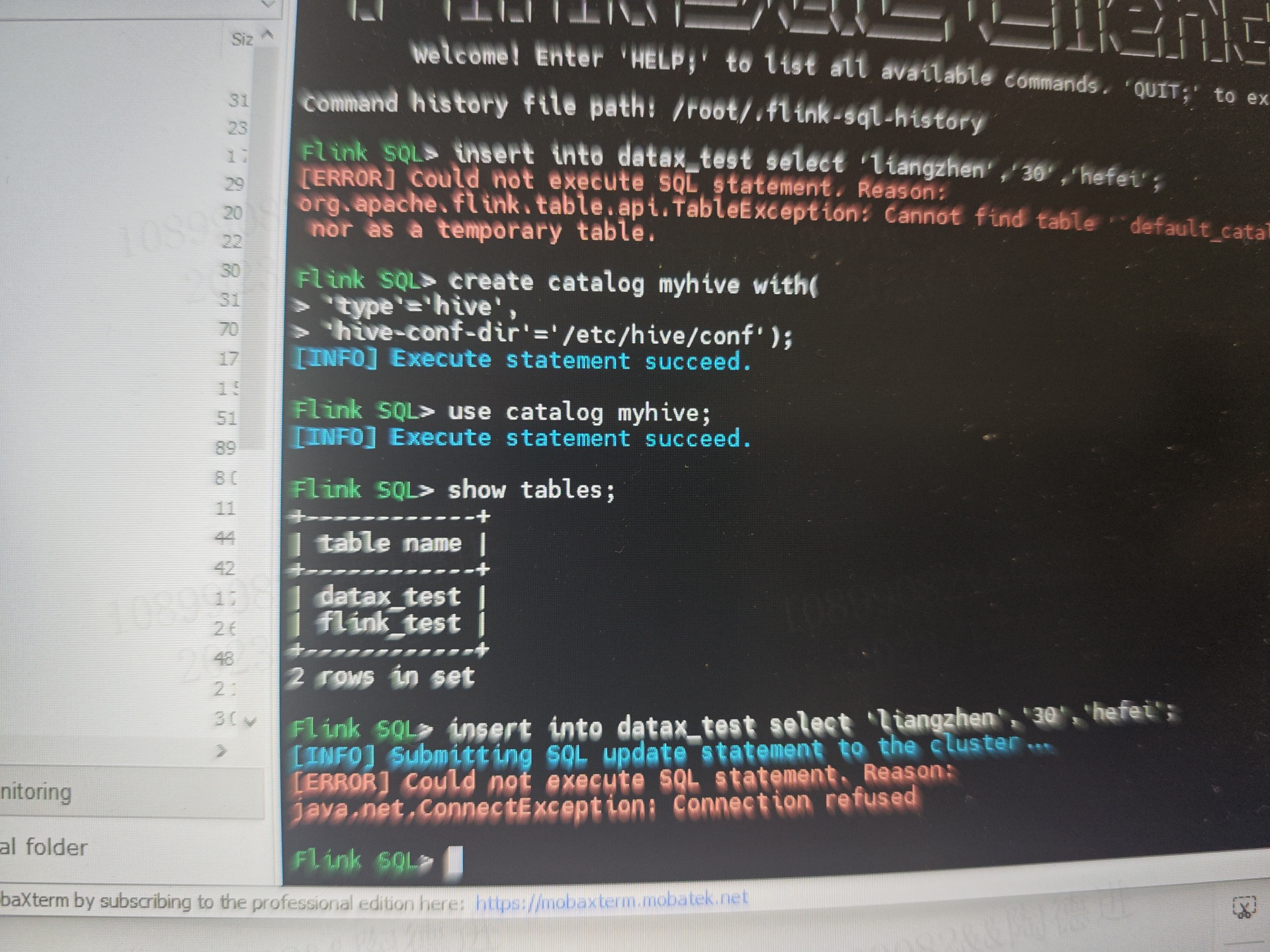
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题以及知识库中的相关资料,以下是对您问题的详细解答:
Flink CDC(Change Data Capture)主要用于捕获数据库中的变更数据,并将其同步到目标存储系统中。然而,Flink CDC本身并不直接支持将数据写入Hive。通常情况下,Flink CDC会将数据同步到支持流式写入的存储系统(如Hologres、Kafka等),而Hive作为一个批处理为主的存储系统,其写入方式与Flink CDC的流式写入模式存在一定的不兼容性。
如果您希望将Flink CDC捕获的数据写入Hive,可以通过以下两种方式实现: 1. 间接写入:先将数据写入支持流式写入的中间存储(如Kafka或Hudi),再通过批处理任务将数据加载到Hive。 2. 使用Hudi作为中间层:Hudi支持流式写入,并且可以与Hive无缝集成,因此可以将Flink CDC捕获的数据写入Hudi,然后通过Hive Catalog访问Hudi表。
根据知识库中的信息,以下是可能导致您插入数据失败的原因及解决方法:
解决方法:
CREATE TABLE hudi_table (
id INT,
name STRING,
ts TIMESTAMP(3)
) WITH (
'connector' = 'hudi',
'path' = 'oss://your-bucket/hudi-table',
'table.type' = 'COPY_ON_WRITE'
);
INSERT INTO hudi_table SELECT * FROM cdc_source;
hive.metastore.uris参数未正确设置),Flink无法连接到Hive Metastore,从而导致写入失败。hive-site.xml文件中的hive.metastore.uris参数是否正确配置。示例如下:<property>
<name>hive.metastore.uris</name>
<value>thrift://xx.yy.zz.mm:9083</value>
</property>
基于上述分析,推荐您采用以下步骤解决问题:
CREATE TABLE hudi_table (
id INT,
name STRING,
ts TIMESTAMP(3)
) WITH (
'connector' = 'hudi',
'path' = 'oss://your-bucket/hudi-table',
'table.type' = 'COPY_ON_WRITE'
);
INSERT INTO hudi_table SELECT * FROM cdc_source;
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-version' = '2.3.6',
'hive-conf-dir' = '/path/to/hive-conf',
'hadoop-conf-dir' = '/path/to/hadoop-conf'
);
SELECT * FROM hive_catalog.default.hudi_table;
Flink CDC与Hive的集成需要特别注意版本兼容性和写入模式的适配性。建议您使用Hudi作为中间层,将Flink CDC捕获的数据写入Hudi表,然后通过Hive Catalog访问Hudi表。这样可以有效解决Hive不支持流式写入的问题,同时充分利用Hudi的流式写入能力和Hive的批处理能力。
如果您仍有疑问或需要进一步的帮助,请提供更多上下文信息(如Flink版本、Hive版本、具体错误日志等),以便我们为您提供更精准的支持。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

