
钉钉同一个连接器,同一个动作,偶尔会出现这种 失败的情况?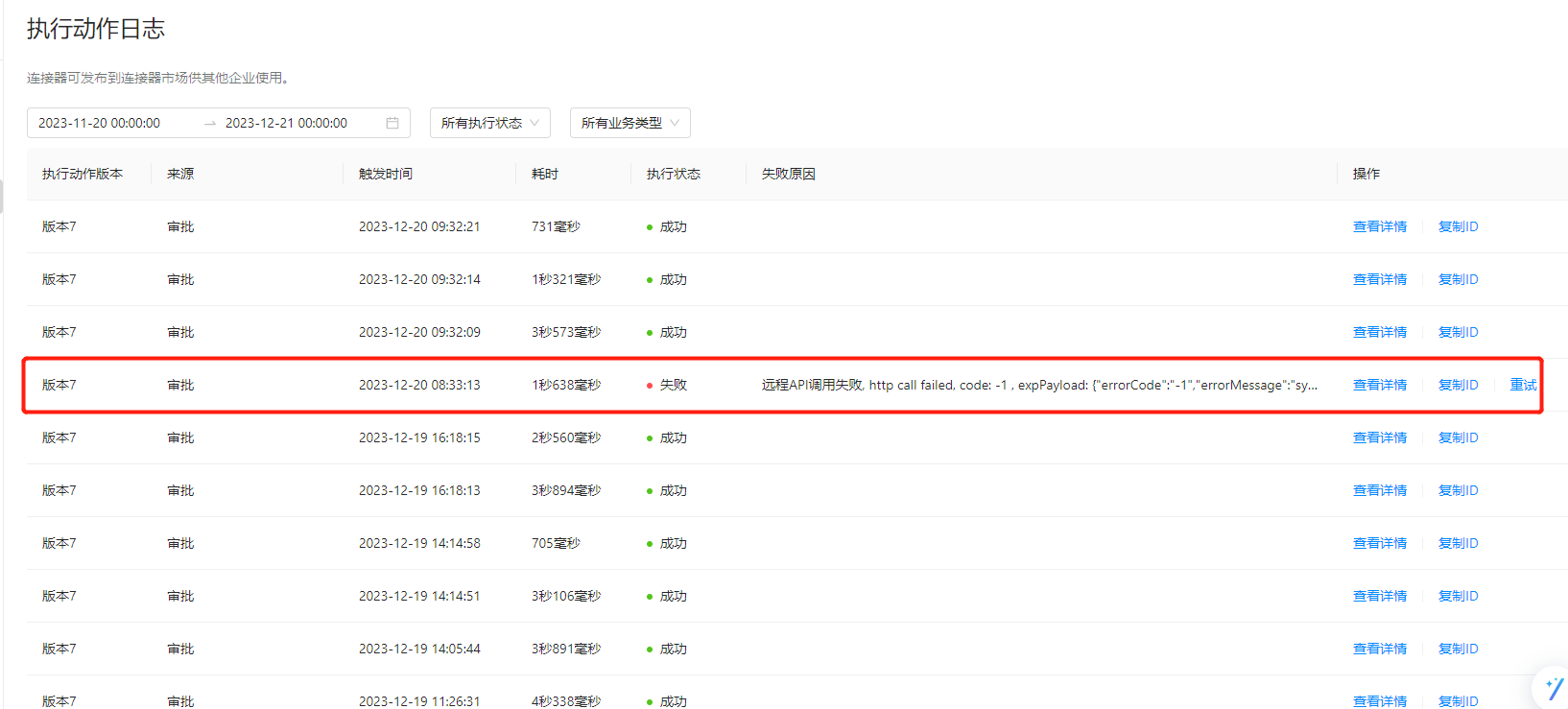
虽然 这里显示失败,但是 现在截图的这个动作,已经正常传递到 后端API中了,也有个别失败,没到API中,请问这个是什么问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,钉钉同一个连接器的同一个动作偶尔会出现失败的情况,但部分失败的动作实际上已经成功传递到后端API中。这种现象可能涉及多个潜在原因,以下是基于知识库资料的详细分析和解决方案:
如果后端服务的连接池资源不足,可能会导致部分请求无法及时处理,从而出现失败的情况。根据知识库中的描述,API网关实例的出访连接池大小有限,当请求量超过连接池容量时,API网关会让请求进入等待队列。如果等待时间超过500毫秒仍未获取到连接资源,则会返回Backend service connect failed Connection lease request time out错误。
api.s1.small规格的最大出访连接池大小为1200,若请求量超过此限制,建议升级到更高规格的实例。后端服务可能会主动发送FIN包关闭连接,导致部分请求失败。这种情况在2023年8月之前购买的API网关实例中较为常见,因为早期版本未对这种场景进行兼容处理。
网络波动可能导致部分请求未能成功到达后端API。虽然截图显示某些失败的动作已正常传递到后端,但这可能是由于网络延迟或重试机制导致的。
如果连接流中的触发器或执行动作配置不当,可能会导致部分请求未能正确传递到后端API。例如,触发器的事件过滤条件可能未完全匹配,或者执行动作的入参配置存在错误。
为了进一步定位问题,建议通过日志和监控工具分析失败请求的具体原因。
综上所述,钉钉连接器动作偶尔失败的原因可能包括后端服务连接池不足、后端服务主动关闭连接、网络波动、配置问题等。建议从以下几个方面入手解决问题: 1. 升级API网关实例并优化后端服务响应时间。 2. 检查触发器和执行动作的配置,确保参数正确。 3. 增加重试机制并排查网络环境。 4. 通过日志和监控工具深入分析失败原因。
如果问题仍然存在,建议联系阿里云技术支持团队,提供详细的日志信息以便进一步排查。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。

