
ModelScope看uniasr的介绍,是通用的英语实时模型,具体怎么应用呢?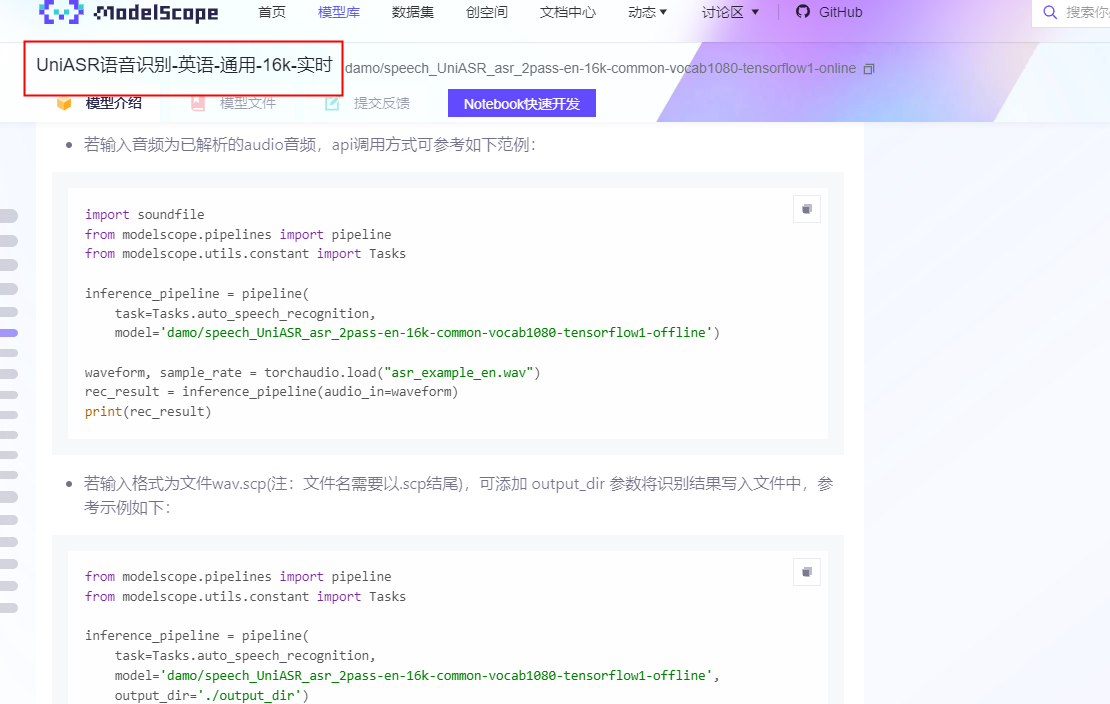
要应用ModelScope中的uniasr模型(通用英语实时语音识别模型),您可以按照以下步骤进行操作。这些步骤涵盖了从模型部署到调用的完整流程,确保您能够快速上手并将其集成到您的应用中。
首先,您需要确认uniasr模型是否满足您的业务需求。根据ModelScope平台的描述,uniasr是一个通用的英语实时语音识别模型,适用于多种场景,例如会议记录、语音转文字等。
MODEL_ID和相关配置参数。ModelScope支持通过阿里云EAS(弹性推理服务)快速部署模型。以下是两种主要的部署方式:
ml.gu7i.c16m60.1-gu30。MODEL_ID、TASK和REVISION信息。MODEL_ID和其他必要的环境变量。部署完成后,您可以通过API接口调用uniasr模型服务。以下是调用的具体方法:
使用Python代码或curl命令发送POST请求,调用uniasr模型服务。以下是一个示例代码:
import requests
import json
# 配置服务信息
service_url = 'YOUR_SERVICE_URL' # 替换为实际的服务访问地址
token = 'YOUR_SERVICE_TOKEN' # 替换为实际的服务Token
# 构造请求数据
request_data = {
"audio": "BASE64_ENCODED_AUDIO", # 将音频文件转换为Base64编码
"language": "en", # 指定语言为英语
"format": "pcm" # 指定音频格式
}
# 发送POST请求
headers = {"Authorization": token}
response = requests.post(service_url, headers=headers, data=json.dumps(request_data))
# 解析返回结果
result = response.json()
print(result)
audio:音频数据,需以Base64编码形式提供。language:指定语言类型,例如en表示英语。format:音频格式,例如pcm、wav等。通过以上步骤,您可以成功部署并调用ModelScope中的uniasr模型,实现通用英语实时语音识别功能。如果有进一步的问题或需要更详细的指导,请随时联系技术支持团队。
