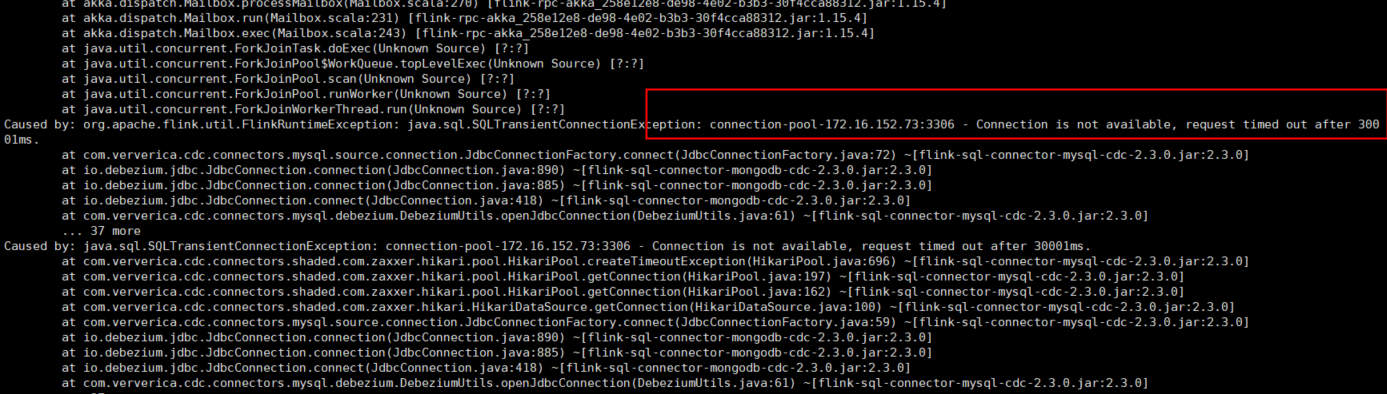
问题1:Flink CDC图中报错是什么原因?
Flink CDC(Change Data Capture)在运行过程中可能会遇到多种报错,具体原因需要结合报错信息进行分析。以下是常见的报错原因及解决方法:
1. 表结构变更导致的同步失败
- 原因:如果在CDC同步期间发生了不支持的表结构变更(如新增列、修改列类型等),可能会导致作业报错或同步失败。
- 解决方案:
- 停止当前作业。
- 删除下游表。
- 重新无状态启动同步作业。
- 避免在同步过程中进行不兼容的表结构变更。
2. Source端出现finish split response timeout异常
- 原因:Task的CPU使用率过高,导致无法及时响应Coordinator的RPC请求。
- 解决方案:
- 在资源配置页面增加Task Manager的CPU资源。
3. 全量阶段发生表结构变更
- 原因:在MySQL CDC全量阶段发生表结构变更,可能导致作业报错或无法同步表结构变更。
- 解决方案:
- 停止作业。
- 删除下游表。
- 无状态地重新启动作业。
4. MongoDB CDC相关问题
- 原因:MongoDB CDC可能因版本不兼容、运行模式不支持或参数配置错误导致报错。
- 解决方案:
- 确认MongoDB版本是否在支持范围内。
- 检查运行模式是否为副本集或分片集群。
- 确保Debezium相关参数正确配置。
5. Postgres CDC相关问题
- 原因:Postgres CDC可能因WAL日志未释放、TOAST数据未传输或DECIMAL类型精度超限导致报错。
- 解决方案:
- 检查Postgres服务器磁盘使用率,清理WAL日志。
- 确保TOAST数据能够被正确传输。
- 调整DECIMAL类型的精度以符合Flink的要求。
6. 网络连通性问题
- 原因:Flink与上下游服务之间的网络不通可能导致timeout或metadata获取失败。
- 解决方案:
- 检查上下游服务与Flink工作空间之间的网络连通性。
- 配置白名单,确保Flink可以访问目标服务。
- 调大
connect.timeout参数的取值。
7. 其他常见报错
- Replication slot active:可能是由于多个任务同时使用同一个replication slot导致冲突。
- Binlog格式不支持:确保MySQL的binlog格式为ROW模式。
- Schema未知:确保CDC连接器能够正确识别表的schema。
问题2:数仓库,source端还要搞CDC?
在数据仓库场景中,source端使用CDC(Change Data Capture)是必要的,原因如下:
1. 实时数据同步需求
- 数据仓库通常需要从多个数据源(如MySQL、PostgreSQL、MongoDB等)实时捕获增量数据,CDC技术能够捕获数据库中的变更事件(INSERT、UPDATE、DELETE),并将其同步到数据仓库中。
- 如果仅依赖批量同步,会导致数据延迟较高,无法满足实时分析的需求。
2. 减少对源库的影响
- CDC通过读取数据库的日志(如MySQL的binlog、PostgreSQL的WAL日志)来捕获变更,避免了直接查询源库带来的性能开销。
- 相比于定时全量同步,CDC对源库的压力更小。
3. 支持复杂的数据处理逻辑
- Flink CDC可以将捕获的变更数据流式处理,支持复杂的ETL操作(如过滤、聚合、转换等),并将结果写入目标数据仓库。
- 这种方式能够实现数据的实时清洗和加工,提升数据仓库的数据质量。
4. 支持多源异构数据集成
- 数据仓库通常需要集成多种异构数据源(如关系型数据库、NoSQL数据库等),Flink CDC支持多种数据源的增量数据捕获,能够统一处理不同来源的数据。
5. 保障数据一致性
- CDC能够捕获源库中的所有变更,确保数据仓库中的数据与源库保持一致,避免因批量同步导致的数据丢失或重复。
总结
- Flink CDC报错的原因可能涉及表结构变更、资源不足、网络问题或配置错误,需根据具体报错信息逐一排查。
- source端使用CDC是为了实现实时数据同步、减少对源库的影响、支持复杂数据处理逻辑以及保障数据一致性,是数据仓库场景中的关键技术。
如果您有具体的报错信息或场景需求,可以进一步提供详细信息,以便我们为您提供更精准的解决方案。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。