
Flink CDC中transform里面的source支持多张表吗?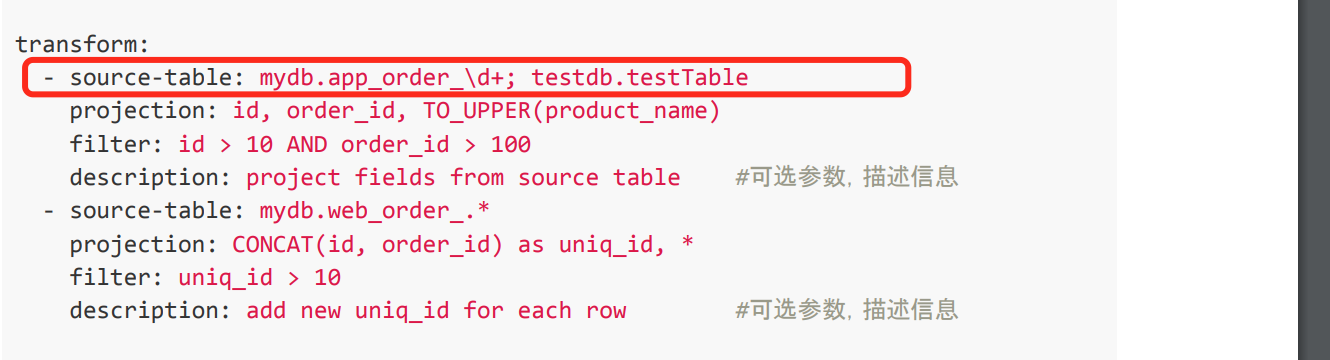
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC中,transform中的source确实支持多张表的读取和处理。以下是详细的说明和实现方式:
Flink CDC通过正则表达式匹配的方式支持从多个数据库或表中读取数据。具体来说,可以通过配置database-name和table-name参数来指定需要同步的库名和表名,并使用正则表达式匹配多个库或表。
CREATE TABLE products (
db_name STRING METADATA FROM 'database_name' VIRTUAL,
table_name STRING METADATA FROM 'table_name' VIRTUAL,
operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL,
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = '(^(test).*|^(tpc).*|txc|.*[p$]|t{2})', -- 正则匹配多个库
'table-name' = '(t[5-8]|tt)' -- 正则匹配多张表
);
说明: - database-name 和 table-name 支持正则表达式匹配多个库或表。 - 匹配模式为 database-name.table-name,例如 (^(test).*|^(tpc).*|txc|.*[p$]|t{2}).(t[5-8]|tt) 可以匹配到 txc.tt 和 test2.test5 等表。
在分库分表合并的场景下,Flink CDC可以将多个分库分表的数据合并到一张目标表中。这通常用于业务数据分散在不同数据库或表中的情况。
CREATE TEMPORARY TABLE mysql_orders (
db_name STRING METADATA FROM 'database_name' VIRTUAL,
table_name STRING METADATA FROM 'table_name' VIRTUAL,
operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL,
op_type STRING METADATA FROM 'op_type' VIRTUAL,
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'mydb_.*', -- 正则匹配多个分库
'table-name' = 'orders_.*' -- 正则匹配多张分表
);
INSERT INTO holo_orders
SELECT * FROM mysql_orders;
说明: - 通过元数据列(如 database_name 和 table_name),可以在合并后的数据中区分每条记录的来源库和表。 - 合并后的数据可以直接写入下游的目标表(如 Hologres)。
如果需要同步多个表,可以使用 STATEMENT SET 语法将多个 CTAS 语句作为一个作业提交。这种方式可以复用同一个 Source 节点,减少对数据库的连接数和读取压力。
USE CATALOG holo;
BEGIN STATEMENT SET;
-- 同步 web_sales 表
CREATE TABLE IF NOT EXISTS web_sales
AS TABLE mysql.tpcds.web_sales
/*+ OPTIONS('server-id'='8001-8004') */;
-- 同步 user 分库分表
CREATE TABLE IF NOT EXISTS user
AS TABLE mysql.`wp.*`.`user[0-9]+`
/*+ OPTIONS('server-id'='8001-8004') */;
END;
说明: - 使用 STATEMENT SET 提交多个 CTAS 语句时,要求这些 Source 表的配置完全一致,才能进行复用优化。 - 这种方式特别适用于 MySQL CDC 数据源场景,能够显著降低对数据库的压力。
在 Flink CDC 中,如果需要动态捕获新增的表,可以通过以下步骤实现: 1. 在 SQL 作业开发时,增加以下配置以开启新增表读取功能:
SET 'table.cdas.scan.newly-added-table.enabled' = 'true';
CTAS 语句,并重新部署作业。限制: - 新增表功能仅支持 initial 启动模式。 - 新增的 CTAS 语句必须与原有 Source 配置完全一致。
table-name 和 database-name 不支持使用逗号分隔多个表或库,需使用竖线(|)连接并用小括号包围,例如 (user|product)。综上所述,Flink CDC 的 transform 中的 source 支持多张表的读取和处理,且提供了多种优化方式(如正则匹配、STATEMENT SET 优化等)来满足复杂场景的需求。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

