
机器翻译中,bad case 这个阿尔巴尼亚语识别有问题该怎怎么解决?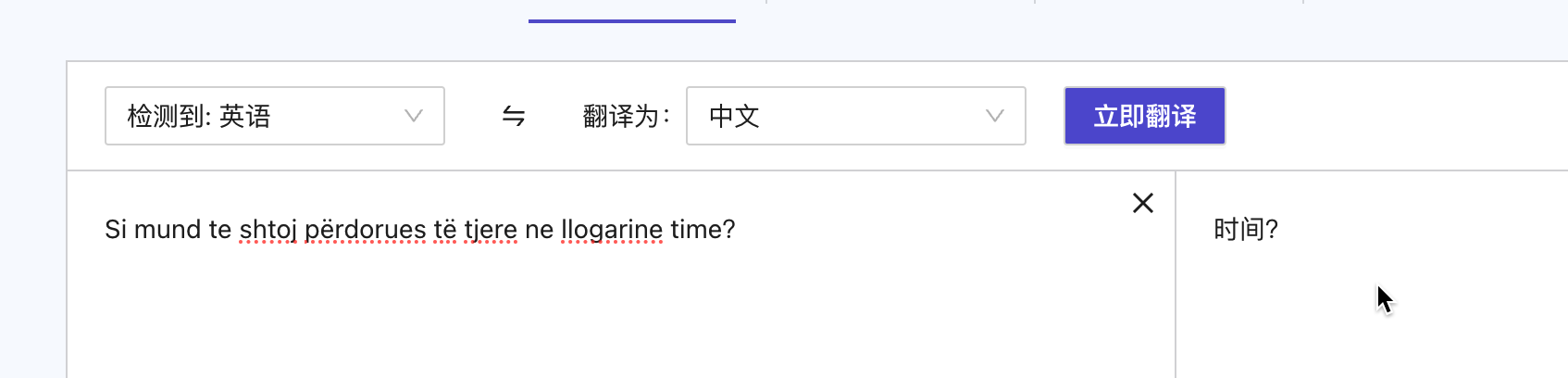 我在界面上操作的:06B6B634-DF09-4FA4-BA85-9F84FBD78EE5
我在界面上操作的:06B6B634-DF09-4FA4-BA85-9F84FBD78EE5
再看看这个 02E7545D-4B3A-3E78-ACA1-35F891C11A3F ,语言识别返回的都是null
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
数据预处理:检查输入的阿尔巴尼亚语文本是否存在错误、拼写错误、缺失标点符号等问题。对于不规范或错误的文本,可以进行预处理和纠正,以提高识别的准确性。
语言模型和训练数据:检查机器翻译系统所使用的语言模型和训练数据,确保涵盖了丰富、准确的阿尔巴尼亚语数据。如果存在缺乏或质量较差的训练数据,可以尝试增加或改进训练数据,以提高识别和翻译的质量。
专业术语和领域适应:阿尔巴尼亚语在特定的领域和专业术语方面可能存在一些特殊的要求。可以通过构建和使用领域相关的术语库,或者增加特定领域的训练数据,以提高对特定领域的识别和翻译效果。
翻译后编辑:对于阿尔巴尼亚语识别问题较为严重的情况,可以考虑在机器翻译后引入人工编辑的环节。通过人工编辑和校对翻译结果,可以修正识别问题,提高翻译的准确性和流畅度。
反馈和改进:如果使用的是公共的机器翻译系统,可以将问题反馈给阿里云,以便他们改进系统的阿尔巴尼亚语识别和翻译能力。提供具体的问题样例和详细的反馈,有助于改进系统的性能和效果。

