
在文字识别OCR自定义模板,时间总是别错误,怎么回事?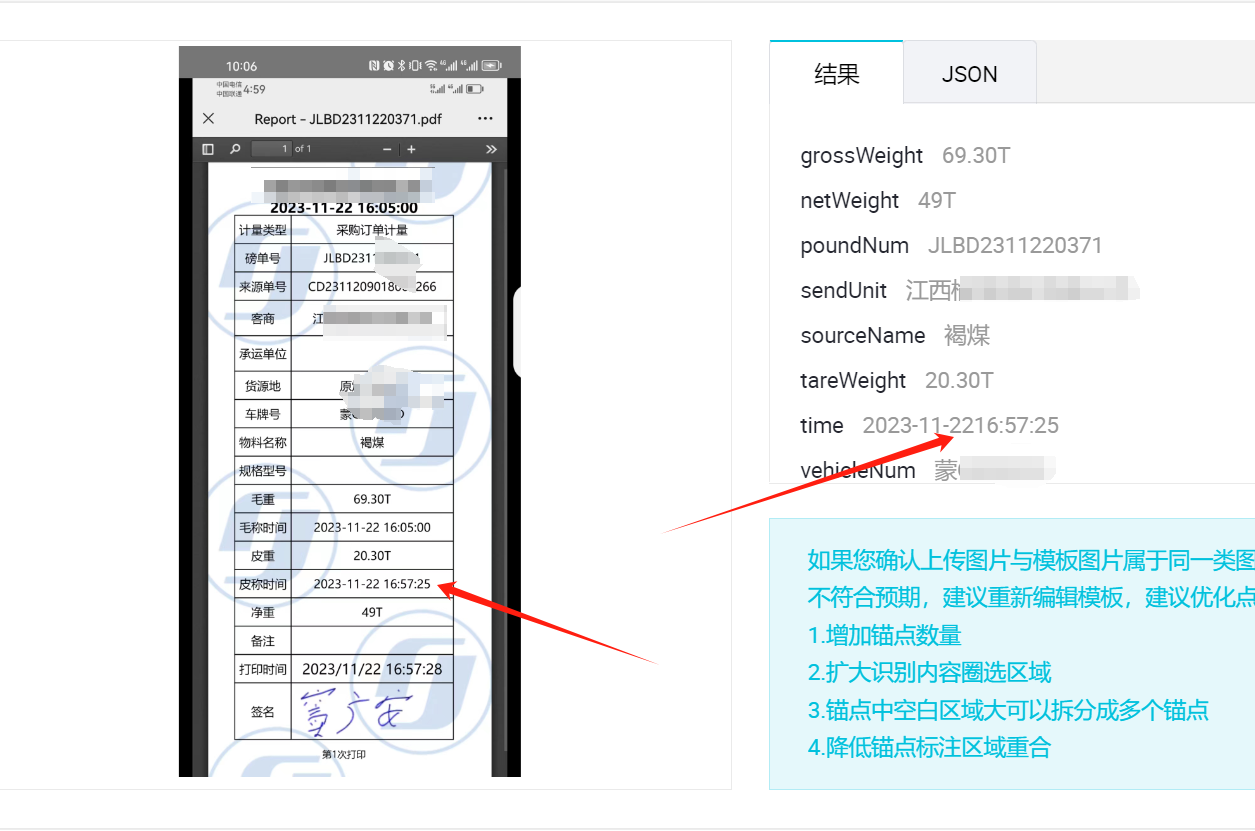 https://ocr.data.aliyun.com/?spm=a1z3lk.11873153.0.0.21291f38syBo4M#/templateEdit/fbb5a291-58f3-4f2f-8102-ab174b3f66ca1700529633 年月日时分秒 识别时,总把空格抹掉了。
https://ocr.data.aliyun.com/?spm=a1z3lk.11873153.0.0.21291f38syBo4M#/templateEdit/fbb5a291-58f3-4f2f-8102-ab174b3f66ca1700529633 年月日时分秒 识别时,总把空格抹掉了。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在文字识别OCR自定义模板中,时间总是被错误地识别,可能由以下几个原因导致:
图像质量问题:
图像模糊、光照不足或有其他干扰因素可能导致 OCR 系统无法准确识别日期和时间。
模板不匹配:
如果使用的 OCR 服务的预定义模板与您的实际文档格式不符,可能会导致识别失败。
数据格式问题:
如果日期和时间的格式不符合预期(例如年份位置不同、使用了不同的分隔符等),OCR 系统可能无法正确解析。
训练模型局限性:
OCR 系统的识别模型可能存在一定的局限性,对于某些特定类型的字体、字号或者样式可能无法有效识别。
语言支持限制:
如果您正在尝试识别的语言不在 OCR 服务的支持范围内,或者使用的是一种特殊方言或变体,可能会导致识别错误。
这个是旧产品不更新了,可以了解新的替代产品,阿里云OCR文档自学习平台。此回答整理自钉群“阿里云读光OCR客户交流反馈群 1”


