
DataWorks离线数据同步脚本模式,对字段值配置了一个变量,但是执行任务的时候,被认定未是字段名,导致报错了, 正确应该怎么配置呢?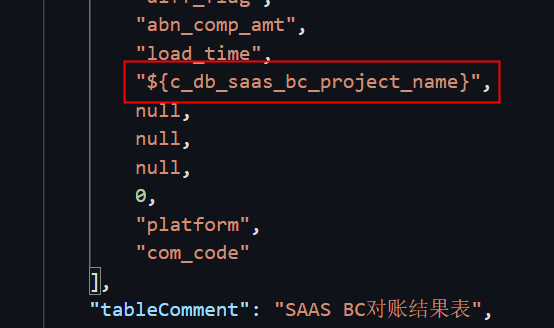
这里原本的逻辑应该是${param} as col_name 的,但是系统把这个${param}认定成col_name了
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云DataWorks的离线数据同步脚本模式中,如果你想为字段值配置一个变量,可以按照以下步骤操作:
登录DataWorks控制台:
选择工作空间:
进入数据开发页面:
创建或编辑任务:
编写SQL语句:
在任务详情页的“代码”区域,编写你的数据同步SQL语句。例如:
SELECT column1, ${your_variable} as column2 FROM your_table
其中${your_variable}是一个占位符,用于表示你想用变量替换的值。
设置变量值:
your_variable的参数,并为其指定默认值或者允许用户在调度时输入值。保存和发布更改:
运行任务:
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


