
现在 flink CDC 支持 schema Evolution 了吗?找了下相关 pull request 貌似还没有合并嘛:
https://github.com/ververica/flink-cdc-connectors/pull/2685
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
目前,Flink CDC 还未正式提供对 Schema Evolution 的支持。您提到的那个 Pull Request 目前还在讨论阶段,尚未被合并到主线分支。
尽管如此,Flink CDC 已经有一些初步的支持,可以让用户实现类似的功能。比如,在 Flink SQL 中,用户可以通过动态修改 Table API 或 SQL 查询来适应 Schema 变更。
例如,在表的某个字段被删除后,可以在查询中直接删除对应的列引用即可继续进行数据同步:
CREATE VIEW new_view AS SELECT id, name FROM old_view;
此外,也有一些社区项目正在探索如何更好地支持 Schema Evolution 功能,例如:
是的,Flink CDC现在确实支持了Schema Evolution。这个功能通过引入一个名为Schema Evolution的内核来实现,使得Flink Job无需依赖外部服务就能实时同步schema变更。此外,Flink CDC 2.0.0版本也增加了对Schema Evolution的支持。如果数据需要支持 Schema Evolution,那么可以通过利用Binlog的机制来协助实现。
支持啊。
https://help.aliyun.com/zh/flink/product-overview/december-16-2021?spm=a2c4g.11186623.0.i1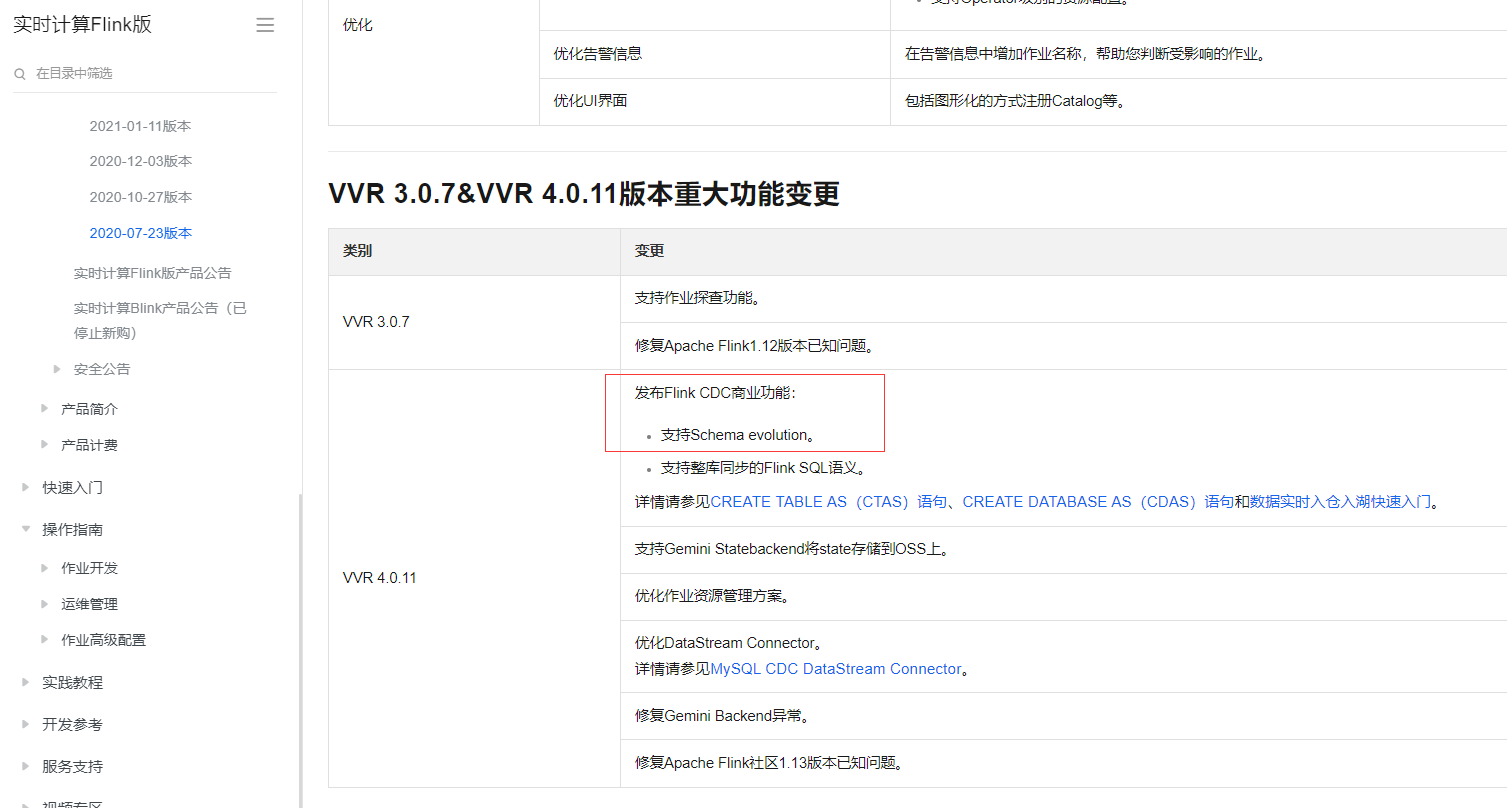
发布Flink CDC商业功能:
支持Schema evolution。
支持整库同步的Flink SQL语义。
详情请参见CREATE TABLE AS(CTAS)语句、CREATE DATABASE AS(CDAS)语句和数据实时入仓入湖快速入门。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


