
大数据计算MaxCompute es可以通过update_time去查询过滤数据,是不是datax脚本的语法不一样? 我在这个search里写march_all是可以拉取的, 如果我要拉取update_time>=2023-10-01 00:00:00 及 update_time<2023-10-02 00:00:00的数据, 这里的json应该怎么写呢?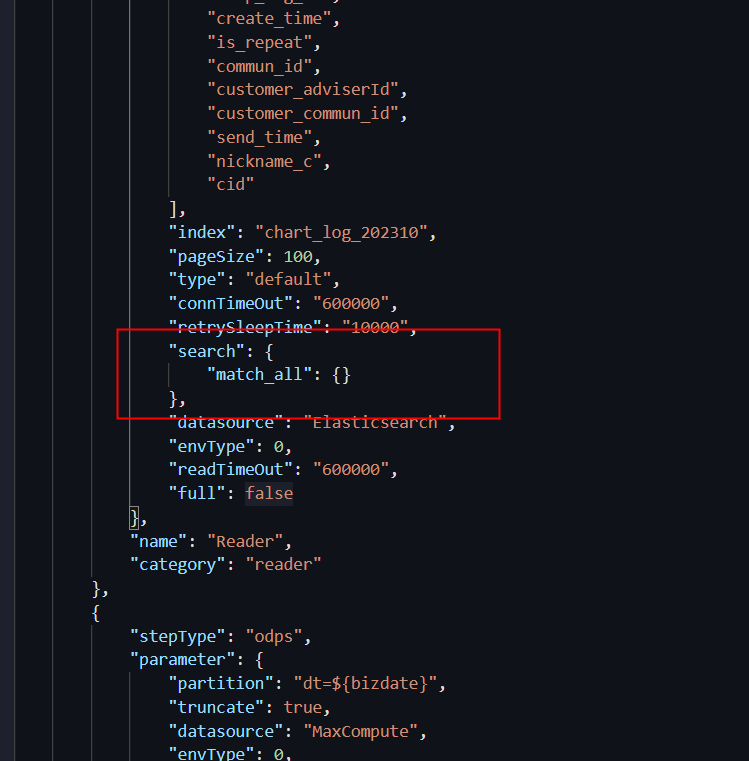
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 MaxCompute 的 SQL 中,你可以使用 WHERE 子句来过滤数据。例如,如果你想查询 update_time 大于等于 '2023-10-01 00:00:00' 且小于 '2023-10-02 00:00:00' 的数据,你可以这样写:
SELECT * FROM table_name
WHERE update_time >= '2023-10-01 00:00:00' AND update_time < '2023-10-02 00:00:00';
请注意,日期和时间值需要用单引号括起来,并且格式必须是 'YYYY-MM-DD HH:MM:SS'。
然后,你可以将这个 SQL 语句传递给 DataX 或者其他数据同步工具,用于拉取符合条件的数据。
在Elasticsearch怎么写,这里就这么写。这里的search是和Elasticsearch的query内容相同的。,此回答整理自钉群“MaxCompute开发者社区2群”
在DataX中,你可以通过定义一个Map类型的配置项column来指定你想要筛选的列名及其条件。具体来说,你可以这样写:
{
"name": "esreader",
"parameter": {
...
"column": [
{"index": "update_time", "condition": ">='2023-10-01 00:00:00'"},
{"index": "update_time", "condition": "<'2023-10-02 00:00:00'"}
]
}
}
这将会把所有update_time字段大于等于'2023-10-01 00:00:00'并且小于'2023-10-02 00:00:00'的数据拉取出来。
注意这里的引号需要是英文半角的单引号或者双引号。
同时记得要确保这个配置项中的其他参数都是正确的,并且可以在你的环境中正常工作。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


