
文字识别OCR只标注了这四个字段,识别率特别低现在,能多上传样本数据提高识别率吗?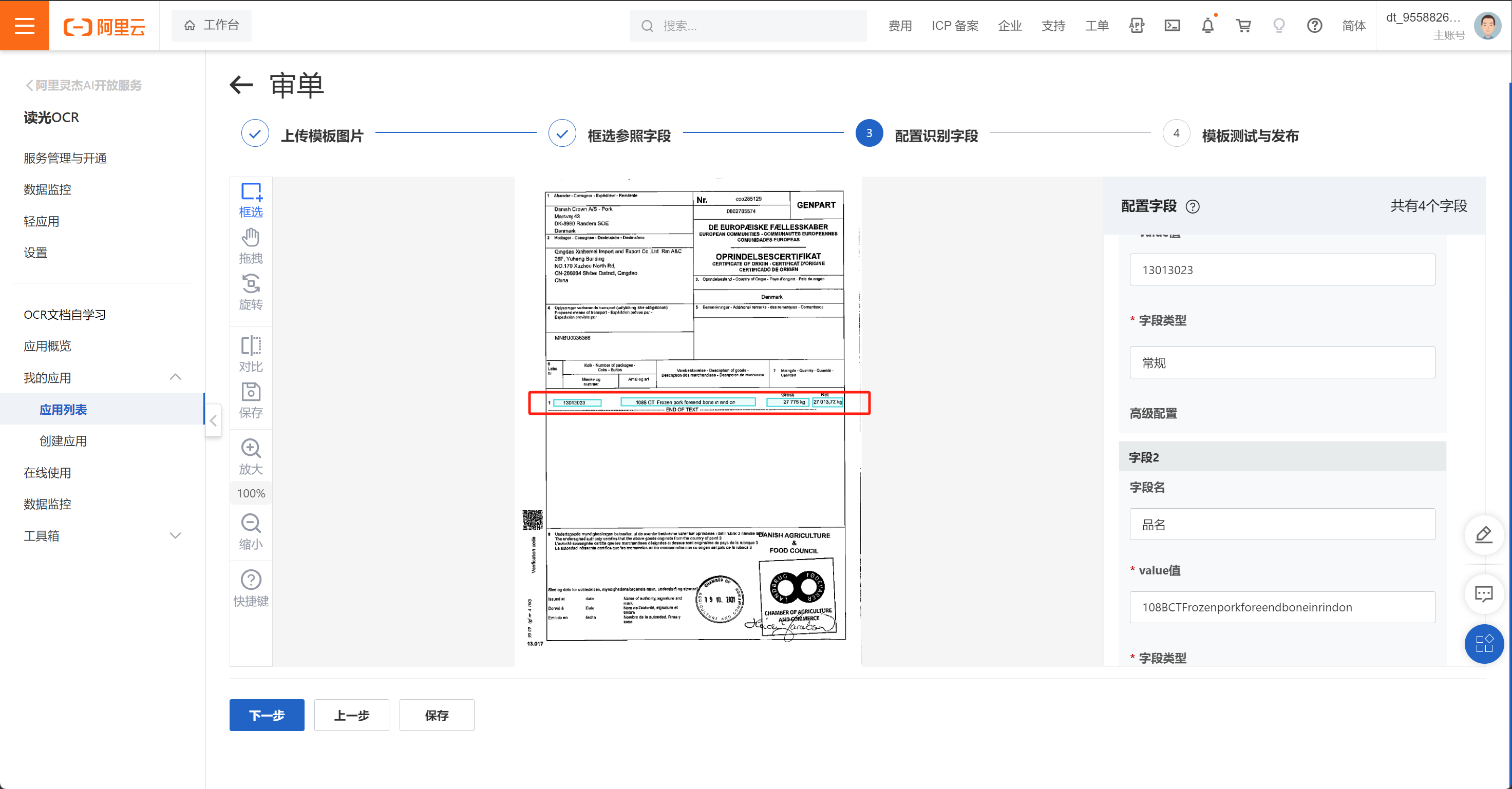
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是的,通过增加更多的训练样本,可以提高模型的识别率。这是因为深度学习模型,如OCR,通常通过大量的训练样本来学习如何从输入数据中提取有用的信息。如果您发现模型在某些特定情况下的识别率较低,那么增加这些情况的训练样本可能会有所帮助。
然而,需要注意的是,仅仅增加训练样本并不总是能提高模型的性能。有时候,可能需要调整模型的结构或参数,或者使用更复杂的模型来处理更复杂的问题。此外,训练样本的选择也很重要,应该尽可能覆盖各种可能的情况,并且样本的质量也应该足够高。
您可以考虑用 单证票据信息抽取 项目,可以标注多样本优化模型效果。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”


