
DataWorks如何读取资源 这块有案例么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 DataWorks 中读取资源主要涉及到两个方面:数据读取和功能调用。
val data = spark.read.csv("/path/to/your/file.csv")
在 Python 语言中,您可以使用 pandas 库来读取 CSV 文件:
import pandas as pd
data = pd.read_csv("/path/to/your/file.csv")
conn = get_dbapi_connection(database="my_database", user="my_user", password="my_password")
with conn.cursor() as cursor:
cursor.execute("SELECT * FROM my_table")
result = cursor.fetchall()
```
以下是 DataWorks 读取资源的一个基本示例,说明了如何使用 Python 脚本来读取一个文件中的数据:在 DataWorks 工作区中创建一个新的 Python 节点:
import pandas as pd
data = pd.read_csv(file_path)
print(data.head())
```
file_path 变量替换为您要读取的实际文件路径。
DataWorks提供了多种数据计算引擎,包括EMR(开源的)和MaxCompute。这些计算引擎可以帮助用户读取各种资源。例如,DataWorks支持将文本文件、Python代码以及 .zip 、 .tgz 、 .tar.gz 、 .tar 、 .jar 等压缩包,作为不同类型的资源上传至MaxCompute,在用户自定义函数UDF及MapReduce的运行过程中读取。
此外,DataWorks还提供了离线同步和实时同步功能,用于实现对数据源的读写操作。例如,离线同步可以通过数据读取(Reader)和写入插件(Writer)来读取数据源,而实时同步则支持将多种输入及输出数据源搭配组成。
附录一:通过命令操作擎项目中的资源https://help.aliyun.com/zh/dataworks/user-guide/create-and-use-maxcompute-resources?spm=a2c4g.11186623.0.i25
常用资源相关操作命令如下。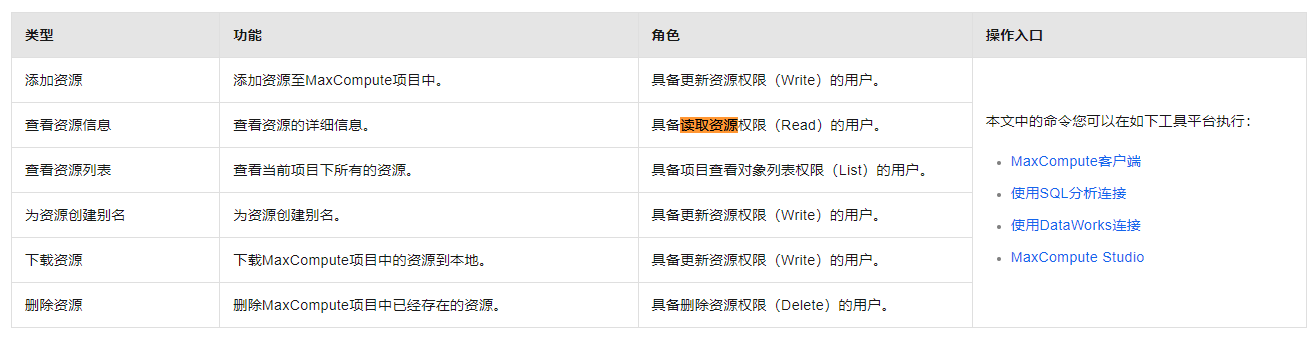
在DataWorks查看资源时,若不添加项目名称,默认查看的是开发项目中的资源。具体如下:
查看当前项目下的所有资源。在DataStudio执行该命令时,默认访问开发环境绑定的MaxCompute项目。
list resources;
查看指定项目下的所有资源。
use MaxCompute项目名称;
list resources;
更多命令操作,详情请参见资源操作。https://help.aliyun.com/zh/maxcompute/user-guide/resource-operations#concept-pps-h1f-vdb
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


