
Flink朴素贝叶斯 这里 是不是有问题呀?
Flink朴素贝叶斯 这里 是不是有问题呀?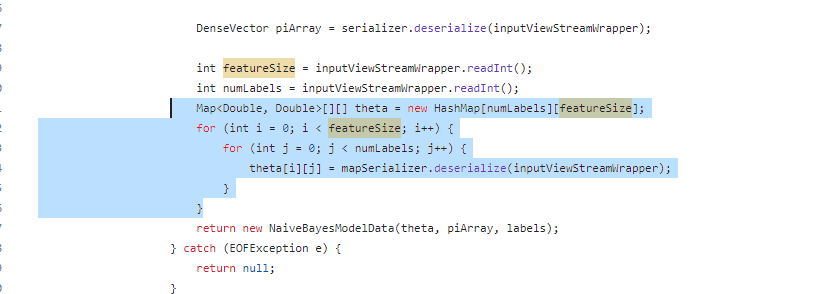
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1
条回答
写回答
-
看起来这段代码是从一个流中反序列化出一些数据,然后构建出一个NaiveBayes模型。这里的
serializer、mapSerializer和inputViewStreamlwrapper可能是自定义的类或者对象,用于进行数据的序列化和反序列化。这段代码的主要逻辑是:首先从输入流中读取特征的数量(featureSize)和标签的数量(numLabels),然后创建一个二维数组
theta,用于存储每个特征在每个标签下的概率。接着,使用mapSerializer从输入流中反序列化出每个标签下的概率,并将其存储到theta数组中。最后,返回一个包含所有反序列化数据的NaiveBayes模型。如果你在运行这段代码时遇到了问题,可能需要查看相关的类和对象的定义,以及它们如何进行数据的序列化和反序列化。
2023-11-09 10:09:53赞同 1 展开评论

问答分类:
问答地址:
开发者社区
>
大数据与机器学习
>
实时计算 Flink
>
问答
相关问答

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理