
我想把resultStream 分别存入hbase和Redis, 为啥flink的流程图是串行的,?
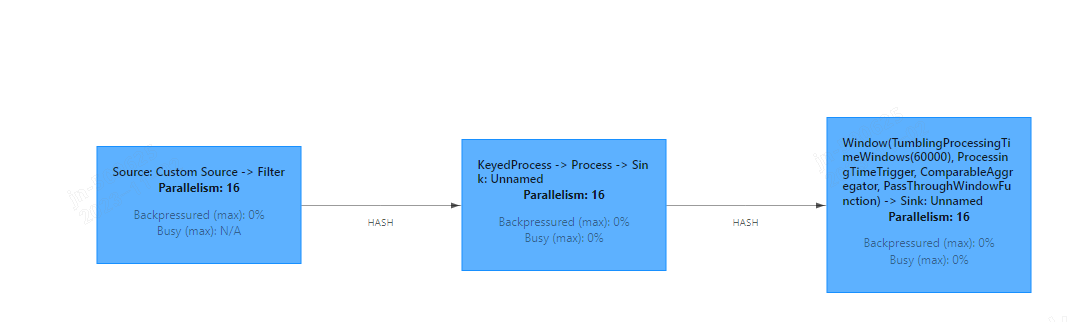
请教一下我想把resultStream 分别存入hbase和Redis, 为啥flink的流程图是串行的, 不是并行的?效果也不是我理解的那样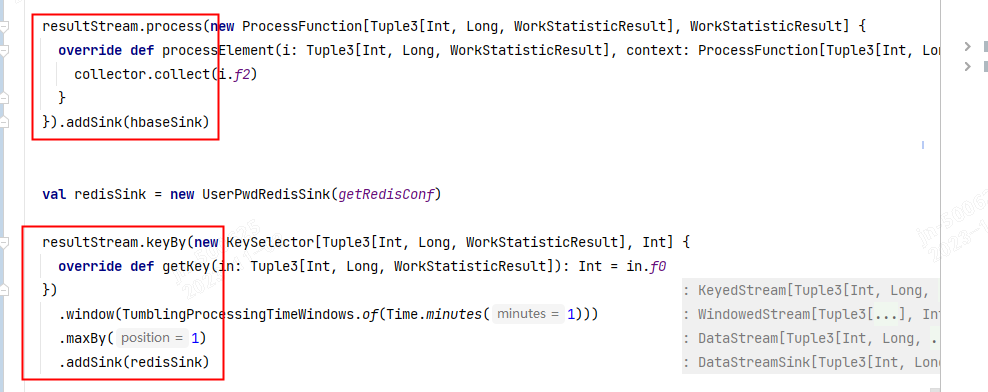
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
在 Flink 中,每个 sink(sink是将流式计算的结果保存到外部系统的组件)都是独立的任务节点,它们之间不会互相干扰,可以并行工作。
2023-11-12 14:06:02赞同 1 展开评论 -
在 Flink 中,数据流通常是串联在一起的,因此,如果您想将一个结果流分发到多个目的地,例如 HBase 和 Redis,通常需要使用有界流来实现。
一个简单的解决方案是使用 sink 拓展机制,即将 Sink 操作符扩展成多个分支,并将结果流分别发送到多个目的地。然而,这样做可能会引起性能下降,因为整个作业必须完成才能开始写入下一个目的地。
另一个方法是使用 Flink’s Union 操作符,将结果流合并为一个新的流,然后使用 FlatMapFunction 或 MapPartitionFunction 分割数据并将其写入不同的目标。这将更好地利用并行度,并且更容易维护和扩展。
以下是示例代码:
DataStream<String> resultStream = ...; // 分别创建两个流处理链路 SingleOutputStreamOperator<Tuple2<String, String>> hbaseSink = resultStream.map(new MapFunction<String, Tuple2<String, String>>() { @Override public Tuple2<String, String> map(String value) throws Exception { return new Tuple2<>(value, value); } }); SingleOutputStreamOperator<Tuple2<String, String>> redisSink = resultStream.map(new MapFunction<String, Tuple2<String, String>>() { @Override public Tuple2<String, String> map(String value) throws Exception { return new Tuple2<>(value, value); } }); // 合并两个流处理链路 DataStream<Tuple2<String, String>> unionStream = StreamUtils.union(hbaseSink, redisSink); unionStream.addSink(new HBaseSink()); unionStream.addSink(new RedisSink());在这个例子中,HBaseSink 和 RedisSink 是您自定义的 sink 类,用于将数据写入到各自的系统中。请注意,unionStream 是两个流的结果合并后的单一流。
2023-11-09 22:04:58赞同 展开评论 -
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
Apache Flink 是一个基于事件驱动的数据处理平台,它通过流式处理数据并保证 Exactly-once 语义。因此,当您将一个 resultStream 分别存储到 HBase 和 Redis 时,流程图可能看起来是串行的,但实际上可能是并行的。
实际上,Flink 会在不同的线程中并行处理结果流。即使将结果流分别存储到 HBase 和 Redis 中,也会并行完成。具体而言,Flink 会对 resultStream 进行切分,然后并行地将每部分发送到 HBase 和 Redis。因此,在很多情况下,您可以获得很好的性能。
当然,具体取决于您的应用的规模和需求。如果您想使整个过程并行运行,请考虑使用多个并行流,并对每个流分别设置存储目标。如果您想要控制存储顺序,则可以使用 watermarks 来控制并发级别。2023-11-09 13:23:37赞同 展开评论 -
Flink的流程图是串行的,这意味着所有的操作都在一条线上进行,前一个操作的结果会传递给下一个操作。这是Flink的基本工作原理,也是大多数流处理框架的工作原理。
在你的例子中,你可能希望将resultStream并行地发送到HBase和Redis。然而,Flink目前并没有直接支持这种并行输出。你需要使用两个独立的StreamExecutionEnvironment,并为每个环境定义一个单独的数据源和数据接收器。
以下是一个基本的示例:
StreamExecutionEnvironment env1 = StreamExecutionEnvironment.getExecutionEnvironment(); StreamExecutionEnvironment env2 = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> resultStream1 = env1.fromSource(...); DataStream<String> resultStream2 = env2.fromSource(...); resultStream1.writeUsingOutputFormat(new HBaseOutputFormat()); resultStream2.writeUsingOutputFormat(new RedisOutputFormat()); env1.execute("HBase job"); env2.execute("Redis job");2023-11-09 10:10:41赞同 展开评论 -
中间那个 合成算子链了吧 所以放在一起展示 ,用disableChaining可以断开 。此回答整理自钉群“【①群】Apache Flink China社区”
2023-11-08 21:29:51赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。