
ModelScope中,请问合成语音,200字要22秒,正常吗?能优化不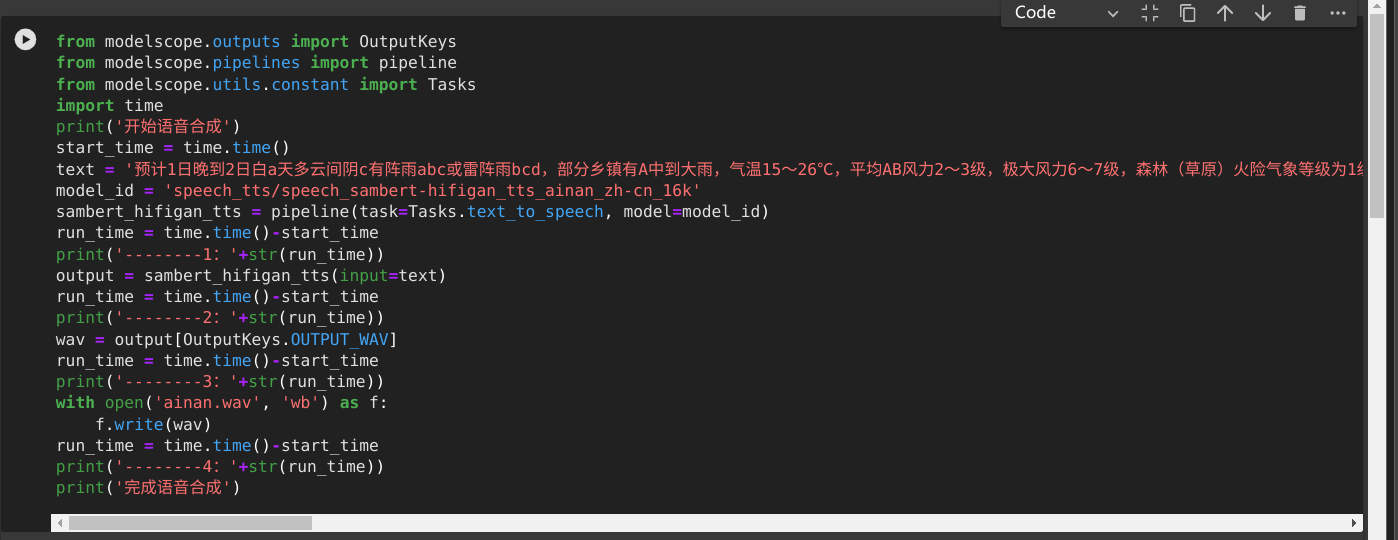
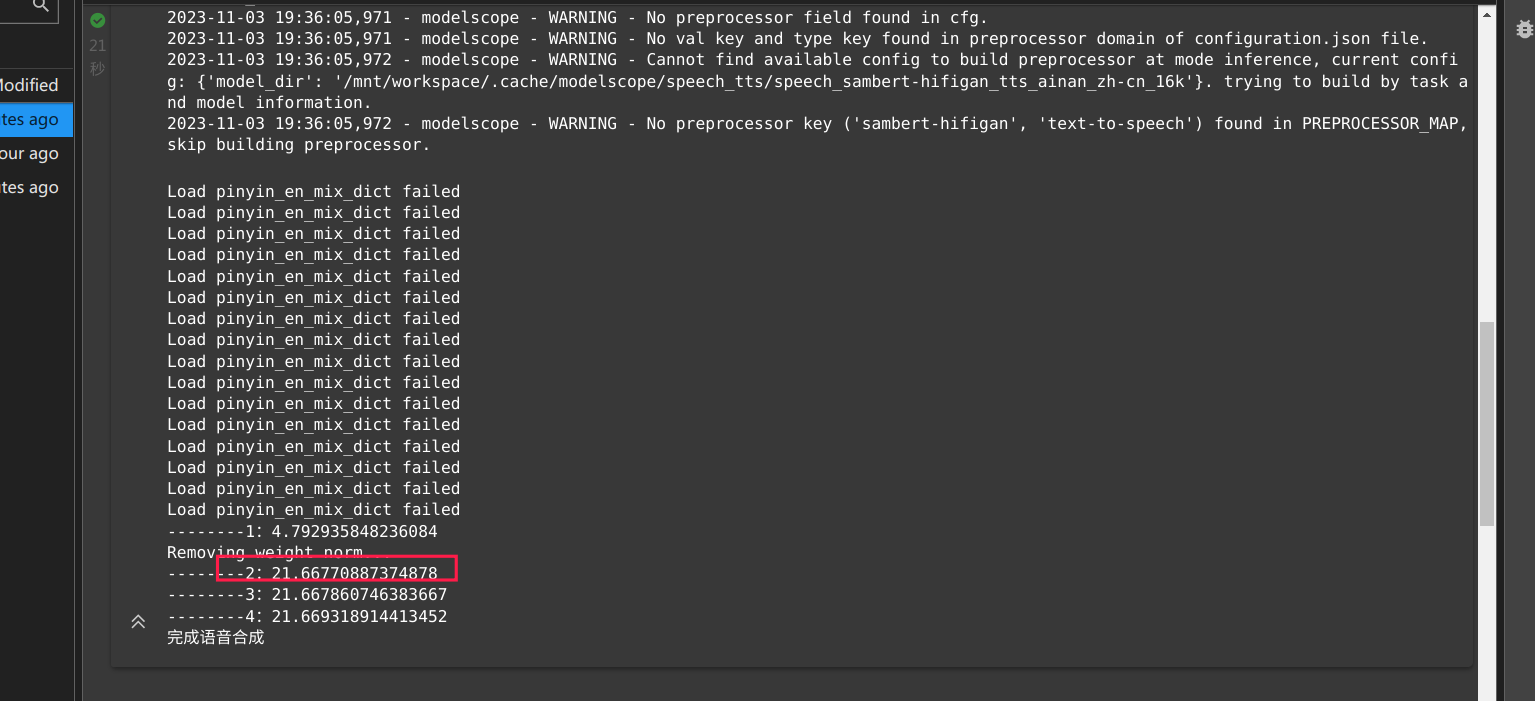
截图里的模型,也是在PAI-DSW GPU环境上运行的
在ModelScope中,合成语音的速度(200字需要22秒)是否正常以及能否优化,取决于多个因素,包括模型的复杂度、硬件配置、推理框架的优化程度等。以下是对问题的详细分析和优化建议:
根据知识库中的信息,语音合成任务的性能通常与以下几个因素相关: - 模型架构:复杂的模型(如基于Transformer的TTS模型)通常会比轻量级模型(如FastSpeech系列)更耗时。 - 硬件配置:如果使用的是GPU环境(如PAI-DSW GPU实例),推理速度会显著快于CPU环境。但具体速度还取决于GPU型号(如V100、A10等)和显存大小。 - 输入长度:语音合成的时间通常与输入文本的长度成正比。200字对应22秒的生成时间,在未优化的情况下是可能的,尤其是对于高精度模型。
因此,200字需要22秒的生成时间在某些情况下是正常的,但仍有优化空间。
为了提升语音合成的速度,可以从以下几个方面进行优化:
tensorflow:1.12PAI-gpu-py36-cu101-ubuntu18.04),以充分利用GPU性能。ecs.gn7i-c8g1.2xlarge)。根据知识库中的描述,截图中的模型很可能是在PAI-DSW GPU环境中运行的。PAI-DSW提供了交互式建模环境,支持多种深度学习框架(如PyTorch、TensorFlow)和硬件加速(如CUDA、cuDNN)。如果您希望进一步验证或优化模型性能,可以参考以下步骤: 1. 登录PAI控制台,进入DSW开发环境。 2. 检查当前实例的硬件配置(如GPU型号和显存大小)。 3. 确认使用的推理框架和模型版本,并尝试切换到更高效的实现。
200字需要22秒的语音合成时间在未优化的情况下是正常的,但通过选择更高效的模型、优化推理框架、升级硬件配置等方法,可以显著提升生成速度。建议您结合实际需求,优先尝试轻量级模型和推理优化工具。如果需要进一步指导,可以提供更多关于模型和硬件的具体信息,以便制定更精准的优化方案。
