
Flink CDC你们cdc配置db.*,如果库里频繁加表,你们是咋操作的,一加表就重启任务?
Flink CDC你们cdc配置db.*,如果库里频繁加表,你们是咋操作的,一加表就重启任务?不生效啊,任务一直运行着,库里新建一个表,如果不重启任务,增量数据都进不去,只能savepoint,然后savepoint恢复任务,不及时恢复任务,那么后面这个表的历史数据会丢失,除非在任务初始化的时候指定表名,全量启动,后面新建的表,再加到配置里,然后恢复启动不会有问题
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
-
mysql有动态加表,动态加表是需要配合savepoint功能的,官网有介绍,代码里很明显这里会清空之前的table-id
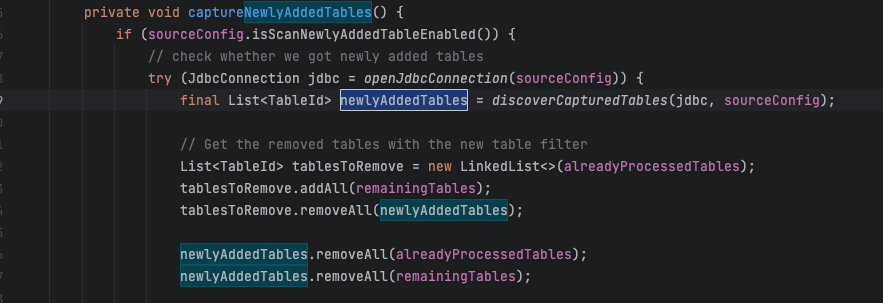
我理解是和.*是没关系的,此回答整理自钉群“Flink CDC 社区”2023-11-08 02:46:05赞同 展开评论 -
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
Flink CDC 在指定 db.* 后不会自动检测表的新建和删除行为,建议尽量不要频繁添加或删除表。如果必须这么做,请参考以下建议:
- 使用 savepoint 功能,以免丢失历史数据;
- 及时恢复任务,在恢复任务时记得加上新添加的表;
- 如果经常添加或删除表,请尽量使用 db. + schema 名称的形式,而不是 db. + 表名的形式;
- 注意 schema 名称的安全性,并保持一致性;
- 避免手动改动 schema ,因为 Flink CDC 并不会检测到 schema 的变动;
- 添加 table filter 功能,可以有效阻止某些不必要的变更事件;
2023-11-07 14:40:14赞同 展开评论 -
你遇到的问题是在使用Flink CDC时,库中频繁添加新表,并且需要实时捕获增量数据,但任务一直运行着,不重启任务就会导致新表的数据无法进入,即使使用savepoint恢复任务,如果不及时恢复也会丢失后面的历史数据。
针对这个问题,可以尝试以下解决方案:
- 定期重启任务:为了使Flink CDC能够捕获到新增表的数据,可以定期(例如每天)重启Flink任务。在重启任务时,可以指定最新的表配置,确保能够捕获到新增表的数据。
- 使用动态配置:为了避免频繁重启任务和丢失历史数据,可以考虑使用动态配置。将表配置信息存储在一个外部系统(如数据库或配置中心)中,并在Flink任务启动时读取最新的配置信息。当有新表添加时,更新配置信息并重新启动Flink任务即可。
- 使用Flink的Table API和Catalog:Flink提供了Table API和Catalog来管理和访问数据库表。可以使用Table API和Catalog来动态地注册和发现数据库表,使Flink CDC能够自动捕获新增表的数据。这样可以避免手动添加表名和重启任务的繁琐过程。
- 实现自定义逻辑:在Flink任务中实现自定义逻辑,通过监听数据库的变化来触发增量数据的捕获。当数据库中有新表添加时,通过自定义逻辑检测到变化并触发捕获操作。这样可以避免频繁重启任务和丢失历史数据的问题。
2023-11-07 10:27:03赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。