
ModelScope魔搭手写体识别 构造lmdb格式时图片的二进制是文件二进制还是opencv读入二进制是RGB通道还是BGR通道呀?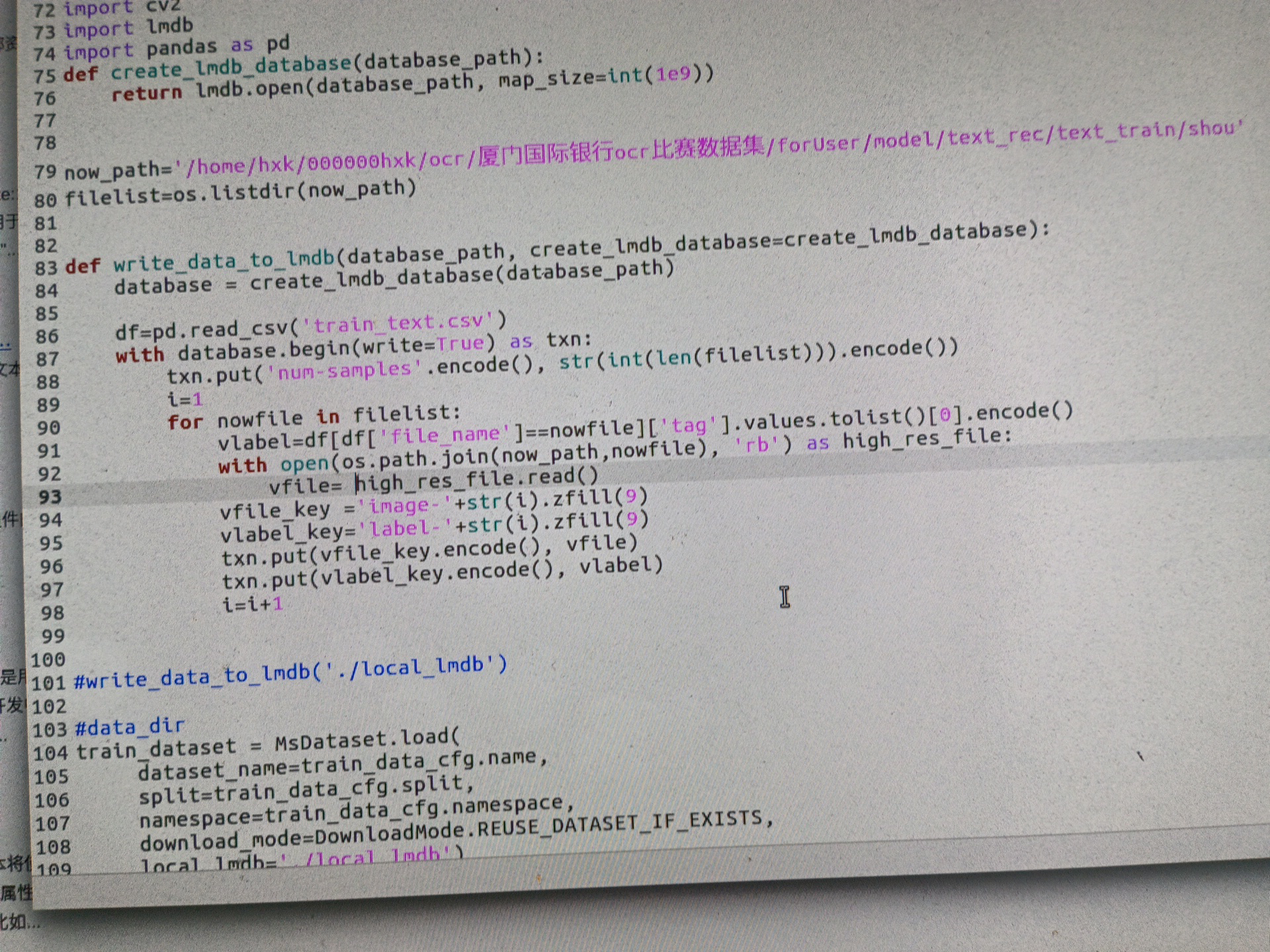
我试了文件方式 好似准确率下降了,能给个造lmdb对应的例子吗?
为了构建 LMDB 数据库,您可以在 OpenCV 中读取图片,并将图片转换成指定的二进制格式。通常来说,LMDB 格式需要将图片以 BGR 格式编码为二进制,以便构建 LMDB 数据库。
ModelScope魔搭手写体识别使用lmdb格式时,图片需要转化为二进制数据。图片的二进制文件格式必须是BGR顺序。您可以使用 OpenCV 的imencode()方法将图像保存为二进制数据,并使用 imdecode() 方法将图像解码回 BGR 格式。另外,请确保您的图片格式正确,并遵循正确的格式要求。如果您使用JPEG或PNG格式,请确保二进制数据正确编码。
在构造lmdb格式时,图片的二进制应该是文件二进制。关于通道顺序,OpenCV读取的图片是BGR通道,而lmdb格式要求的是RGB通道。所以需要将图片从BGR通道转换为RGB通道。
以下是一个使用Python和OpenCV构造lmdb格式的例子:
import cv2
import numpy as np
from lmdb import env, lock, open_dict
# 设置图片路径和输出lmdb文件路径
image_path = 'path/to/your/images'
output_lmdb = 'path/to/your/output.lmdb'
# 创建lmdb环境
env = env.create(output_lmdb)
# 打开lmdb字典
with open_dict(env, output_lmdb) as d:
# 遍历图片文件夹
for i, filename in enumerate(os.listdir(image_path)):
# 读取图片并转换通道顺序
image = cv2.imread(os.path.join(image_path, filename))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 将图片数据转换为字节流
key = f'{i:08d}'
d[key] = image.tobytes()
这个例子中,我们首先导入所需的库,然后设置图片路径和输出lmdb文件路径。接着创建lmdb环境并打开字典。在遍历图片文件夹的过程中,我们读取图片并将其通道顺序从BGR转换为RGB。最后,我们将图片数据转换为字节流并存储到lmdb字典中。
ModelScope魔搭手写体识别使用的通道格式是RGB。在构造lmdb格式时,图片的二进制应该是文件二进制,而不是opencv读入的二进制。
以下是使用Python创建lmdb格式的示例代码:
import os
import lmdb
import numpy as np
from PIL import Image
env = lmdb.open('handwriting_recognition.lmdb')
txn = env.begin(write=True)
for i in range(1000):
# 读取图片
img_path = f'handwriting_{i}.jpg'
img = Image.open(img_path).convert('RGB')
# 将图片转换为numpy数组
img_array = np.array(img)
# 将数组转换为二进制
img_bin = img_array.tobytes()
# 将二进制数据添加到lmdb表中
txn.put(f'image_{i}', img_bin)
txn.commit()
txn = env.begin(write=False)
for i in range(1000):
imgbin = txn.get(f'image{i}')
img_array = np.frombuffer(img_bin, dtype=np.uint8).reshape(28, 28, 3)
img = Image.fromarray(img_array)
img.show()
env.close()
CopyCopy
在这个例子中,我们首先创建了一个lmdb环境,然后在其中创建了一个表。
https://github.com/FudanVI/benchmarking-chinese-text-recognition/blob/main/data/lmdbMaker.py,可以参考下这个,打了个临时的modelscope sdk安装包,可以pip install modelscope-1.9.4-py3-none-any.whl 安装到本地。,此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”

