
Flink CDC每次快照执行完后面的checkpoint就这样了,怎么排查啊?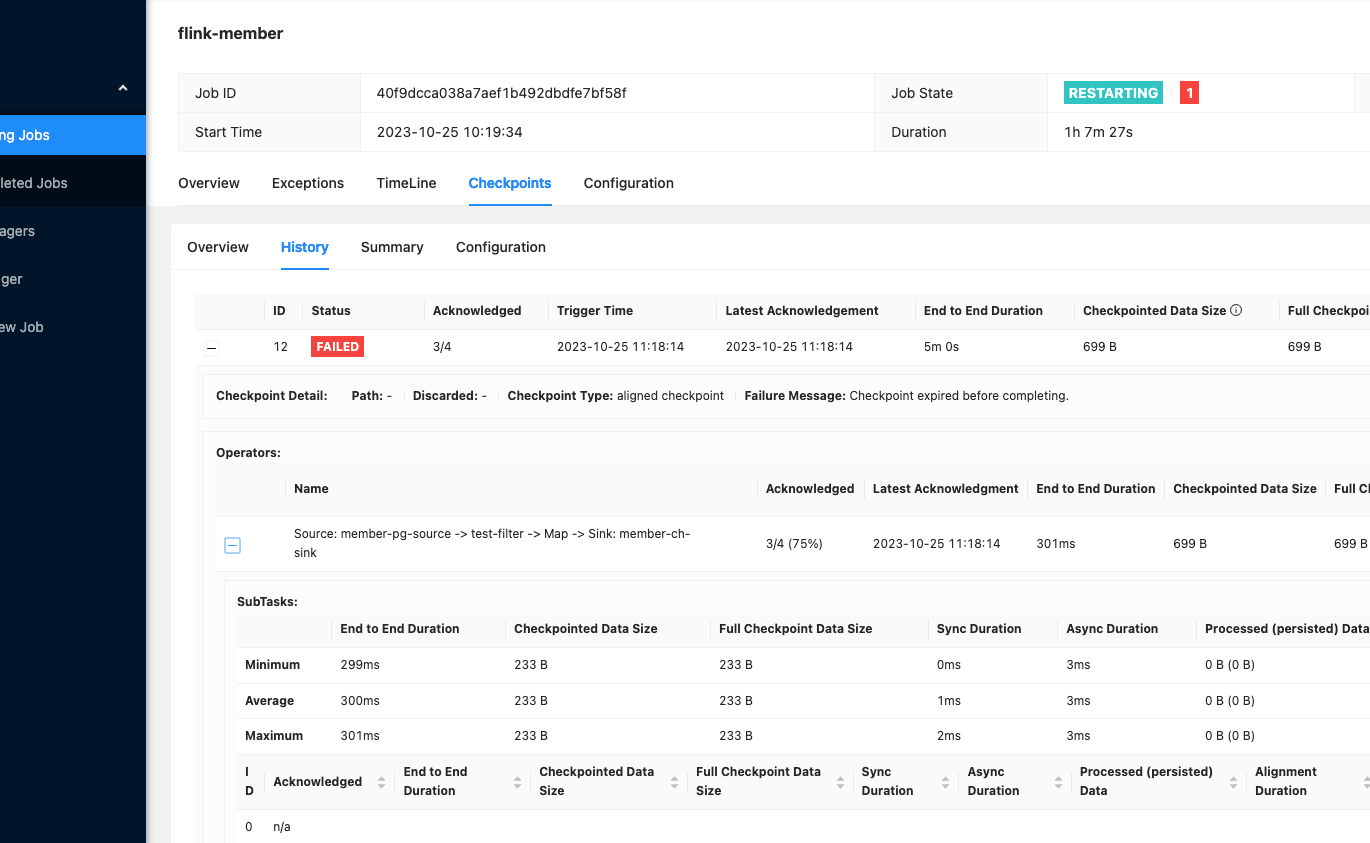
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题“Flink CDC每次快照执行完后面的checkpoint出现问题”,结合知识库中的相关资料,以下是详细的排查和解决方法:
Flink的检查点(Checkpoint)分为同步阶段和异步阶段,需要分别分析这两个阶段的性能表现。
同步阶段:
Sync Duration和Alignment Duration是否较长。异步阶段:
Async Duration和Checkpointed Data Size是否较大。table.exec.state.ttl参数以减少状态数据量,或者升级到更高性能的状态后端(如GeminiStateBackend V4版本)。如果使用的是Postgres CDC连接器,需确保以下配置正确:
增量快照功能:
execution.checkpointing.interval: 10min
execution.checkpointing.tolerable-failed-checkpoints: 100
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2147483647
execution.checkpointing.tolerable-failed-checkpoints的值应根据表大小适当调整,避免因Checkpoint超时导致Failover。Replication Slot管理:
通过Flink运维中心的Checkpoint历史记录,定位具体问题:
End to End Duration列,确认慢Checkpoint对应的ID。如果Checkpoint仍然存在问题,需进一步排查网络和资源相关问题:
网络连通性:
资源分配:
ERROR:exceeded quota: resourcequota如果上述方法无法解决问题,需深入分析日志信息:
Job Manager异常:
失效Task Managers日志:
根据知识库中的说明,Checkpoint的触发时间受以下两个参数影响:
<上一次开始时间,下一次开始时间>的最小时间差。<上一次结束时间,下一次开始时间>的最小时间差。建议根据实际业务场景调整这两个参数,避免Checkpoint过于频繁或间隔过长。
如果问题仍未解决,请提供具体的错误日志或异常信息,以便进一步分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

