
关于Lindorm中时序预测模型训练的例程中,SETTINGS里有三个参数我没搞明白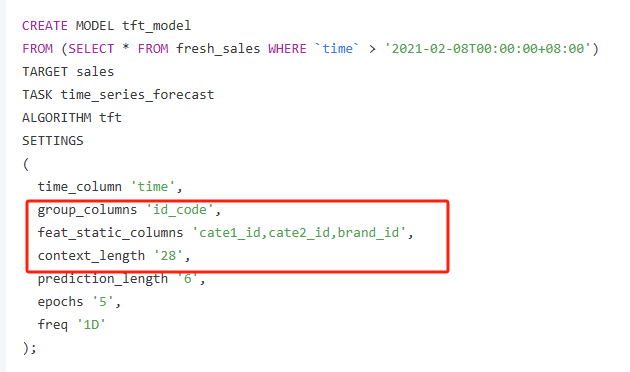
group_columns作用是什么?是自己创建表时必须创建的列吗?
feat_static_columns作用是什么?
context_length相当于指定神经网络的backward_steps吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
问题一:
问题二:
如果文档没有解释清楚,可以尝试查阅其他相关资料或者向Lindorm社区提问以获取更详细的解答。
问题三:
假设time_column的数据间隔是15分钟,预测步长是3,那么group_columns这一列可以是表示时间序列数据的列,例如"timestamp"。这个列的值应该是按照时间顺序递增的整数或日期时间格式。例如,可以使用以下示例数据:
| timestamp | group_columns | value |
|---|---|---|
| 1 | 1 | 10 |
| 16 | 2 | 20 |
| 31 | 3 | 30 |
| 47 | 4 | 40 |
| 61 | 5 | 50 |
在这个例子中,group_columns列的值是按照时间顺序递增的整数序列。
对于Lindorm中时序预测模型训练的例程,您提到的三个参数的具体含义如下:
group_columns:这个参数的作用是用来定义数据中需要进行分组的列。在时序预测中,通常需要对数据进行分组,以便对每个组进行独立的预测。例如,如果您正在预测每个小时的销售额,那么您可以将时间戳作为分组列,以便将数据分为不同的时间组,并对每个组进行预测。在创建表时,您需要确保包含适当的分组列,以便在训练模型时使用。
feat_static_columns:这个参数的作用是用来定义静态特征列。静态特征通常是不随时间变化的特征,例如商品的类别、地理位置等。这些特征可以提供有关数据的重要信息,帮助模型更好地进行预测。您需要在训练模型时指定这些列,并在创建表时确保包含它们。
context_length:这个参数相当于指定神经网络的backward_steps。它定义了模型在预测当前时间步时考虑的历史时间步的数量。例如,如果您设置context_length为3,则模型将考虑最近3个时间步的历史数据来进行预测。
如果time_column的数据间隔是15分钟,而您的预测步长是3,那么group_columns的例子可以是一组连续的数字,例如1、2、3...。这种序列可以用来表示每个时间间隔的数据分组。在这种情况下,您可以将group_columns参数设置为一个整数列表,该列表包含每个时间间隔的开始数字(例如[1, 4, 7, 10, 13, 16, 19, 22, 25, 28])。这样可以让模型了解数据的分组方式,并针对每个分组进行独立的预测。

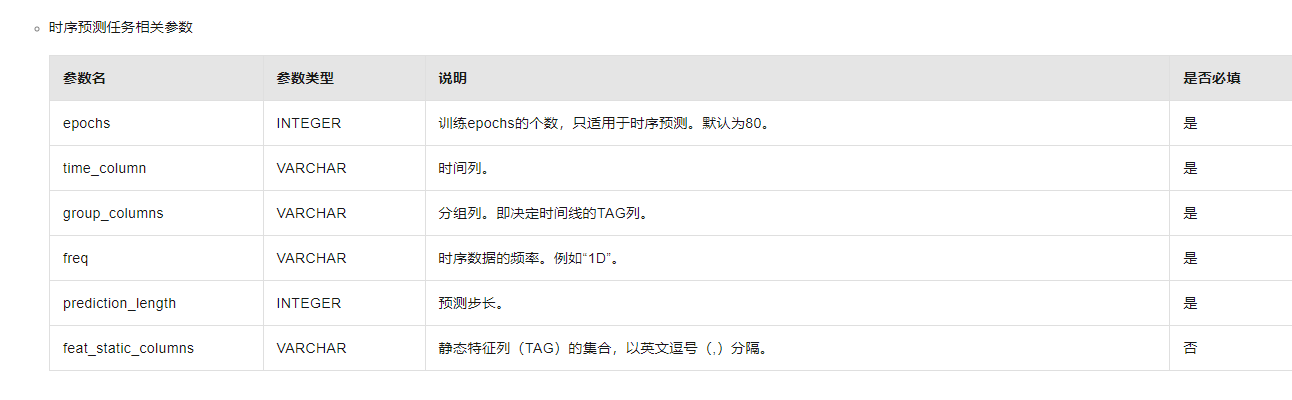
https://help.aliyun.com/document_detail/2401803.html?spm=a2c4g.462398.0.i4
https://help.aliyun.com/document_detail/2401803.html?spm=a2c4g.2399103.0.0.27cb50f1N28QoR#a9b24760225v2 这里文档上有
group_columns是创建表时需要指定的,用于标识时间线;static column是静态特征,就是一些可以让算法辅助学习到的不会随时间变化(静态)的特征,用于提升预测准确率,context_length就是预测时候的历史数据窗口_x005f;group_column是你的时间线的tag,具体数据模型可以参考 https://help.aliyun.com/document_detail/182276.html?spm=a2c4g.180921.0.0.30db33efaFGmdV—此回答来自钉群“Lindorm AI 邀测支持群”
阿里云NoSQL数据库提供了一种灵活的数据存储方式,可以支持各种数据模型,包括文档型、图型、列型和键值型。此外,它还提供了一种分布式的数据处理方式,可以支持高可用性和容灾备份。包含Redis社区版和Tair、多模数据库 Lindorm、MongoDB 版。


