
Flink CDC中有没有遇到这个,检查点超时?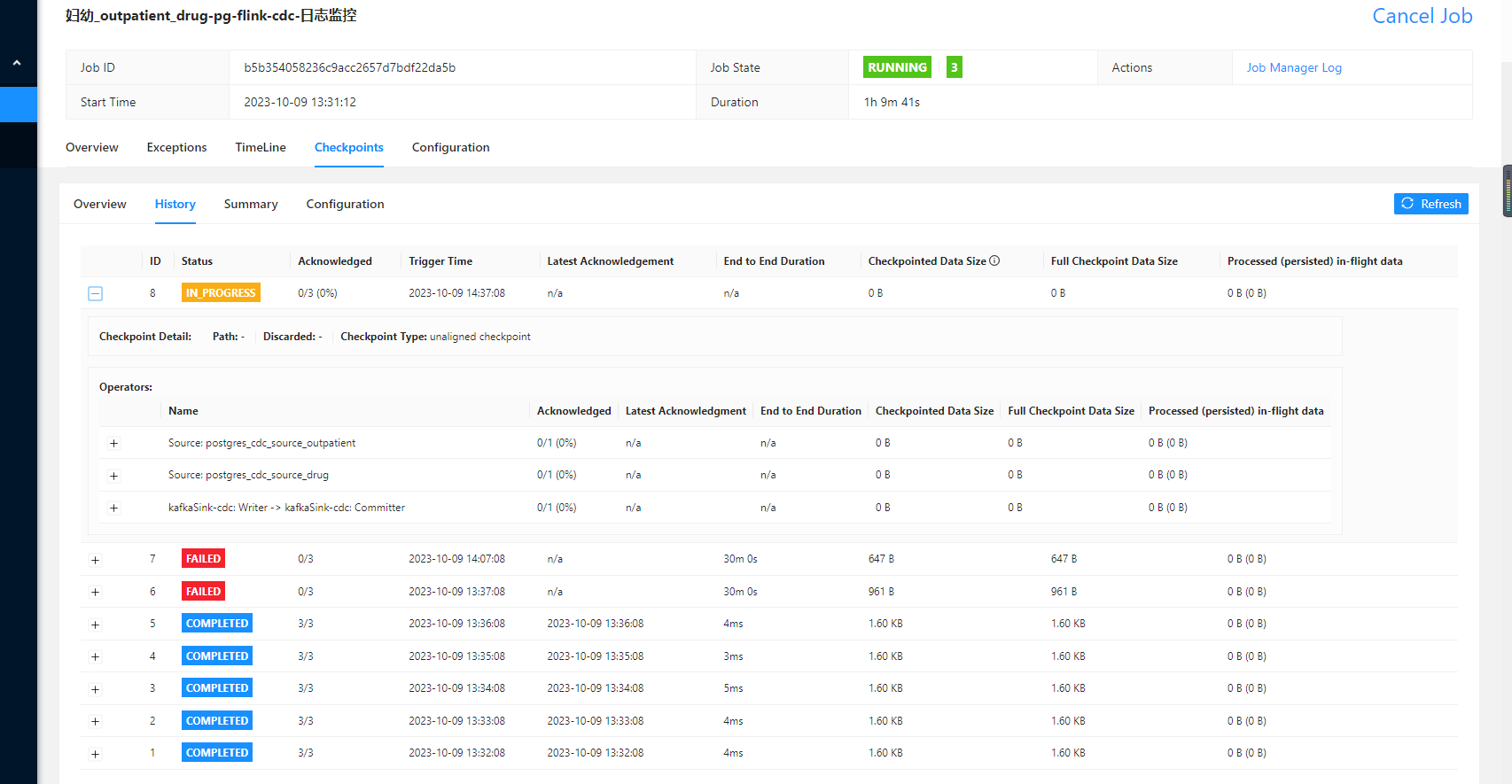
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC时,检查点超时是一个常见的问题,尤其是在数据量较大或网络带宽受限的情况下。根据知识库中的资料,以下是关于Flink CDC中检查点超时的详细分析和解决方案:
Flink的状态管理依赖于Chandy-Lamport算法,检查点的执行分为两个阶段: - 同步阶段:Barrier在算子间传递并对齐,此阶段的延迟与数据记录的延迟成正比。 - 异步阶段:算子将本地状态数据上传至远程持久化存储,上传时间与状态数据大小成正比。
如果检查点超时,可能的原因包括: - 同步阶段瓶颈:Barrier对齐时间过长,通常由反压(Backpressure)引起。 - 异步阶段瓶颈:状态数据过大导致上传时间过长。 - MySQL Binlog机制的影响:即使只读取部分表的数据,Binlog仍会记录整个实例的所有变更,可能导致带宽消耗过高,从而影响检查点的完成。
在运维中心 > 作业运维页面的“作业日志”页签下,通过“Checkpoints” > “Checkpoints 历史”观察不同级别的Checkpoint指标: - Sync Duration 和 Alignment Duration 较长:表明瓶颈在同步阶段,需优化同步过程。 - Async Duration 较长,Checkpointed Data Size 较大:表明瓶颈在异步阶段状态上传,需优化状态数据处理。
在运维中心 > 作业运维页面的“监控告警”页签下,查看以下指标: - lastCheckpointDuration:历史Checkpoint的耗时。 - lastCheckpointSize:历史Checkpoint的大小。 通过这些指标可以粗粒度分析检查点的性能瓶颈。
调整Checkpoint间隔和失败容忍度:
execution.checkpointing.interval和execution.checkpointing.tolerable-failed-checkpoints的值,避免在全量同步阶段由于Checkpoint超时导致Failover。execution.checkpointing.interval: 10min
execution.checkpointing.tolerable-failed-checkpoints: 100
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2147483647
execution.checkpointing.interval定义了Checkpoint的时间间隔,execution.checkpointing.tolerable-failed-checkpoints定义了允许的Checkpoint失败次数。开启增量快照:
复用CDC Source:
timestamp字段时出现时区偏差,确保在CDC作业中正确配置server-time-zone参数,使其与MySQL服务器时区一致。通过上述诊断方法和优化策略,您可以有效解决Flink CDC中的检查点超时问题,提升作业的整体性能和稳定性。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

