"OpenKruise中我在开发中想使用kruise的CRR功能,但是发现提交CRR之后pod处于Recreating状态:
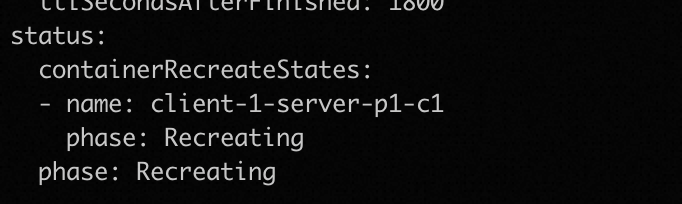
$cat test_remote.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
vxpu.io/adaptive: ""false""
vxpu.io/env: vxpu-server
name: vxpu-example-remote-server-p2
namespace: test-webhook1
spec:
containers:
- command:
- /bin/bash
- -c
- sleep 365d
env:
image: reg.docker.alibaba-inc.com/vodla_ccbrain/hpc_resnet50_batches:v1.0.43-alios7u2-min-1.13-cuda11.4-gcc10.2
imagePullPolicy: IfNotPresent
name: client-1-server-p1-c1
resources:
limits:
kubernetes.io/gpu-core: ""50""
kubernetes.io/gpu-memory: 8Gi
requests:
kubernetes.io/gpu-core: ""50""
kubernetes.io/gpu-memory: 8Gi
nodeSelector:
agentLabel: NV_T4
restartPolicy: Never
schedulerName: koord-scheduler
$cat test-restart.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: ContainerRecreateRequest
metadata:
namespace: test-webhook1
name: vxpu-example-remote-server-p2
spec:
podName: vxpu-example-remote-server-p2
containers: # 要重建的容器名字列表,至少要有 1 个
- name: client-1-server-p1-c1
strategy:
failurePolicy: Fail # 'Fail' 或 'Ignore',表示一旦有某个容器停止或重建失败, CRR 立即结束
orderedRecreate: false # 'true' 表示要等前一个容器重建完成了,再开始重建下一个
terminationGracePeriodSeconds: 30 # 等待容器优雅退出的时间,不填默认用 Pod 中定义的
unreadyGracePeriodSeconds: 3 # 在重建之前先把 Pod 设为 not ready,并等待这段时间后再开始执行重建
minStartedSeconds: 10 # 重建后新容器至少保持运行这段时间,才认为该容器重建成功
activeDeadlineSeconds: 300 # 如果 CRR 执行超过这个时间,则直接标记为结束(未结束的容器标记为失败)
ttlSecondsAfterFinished: 1800 # CRR 结束后,过了这段时间自动被删除掉
这个我的pod和crr的yaml文件。我用的是1.3版本。"

