DataWorks如何补数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
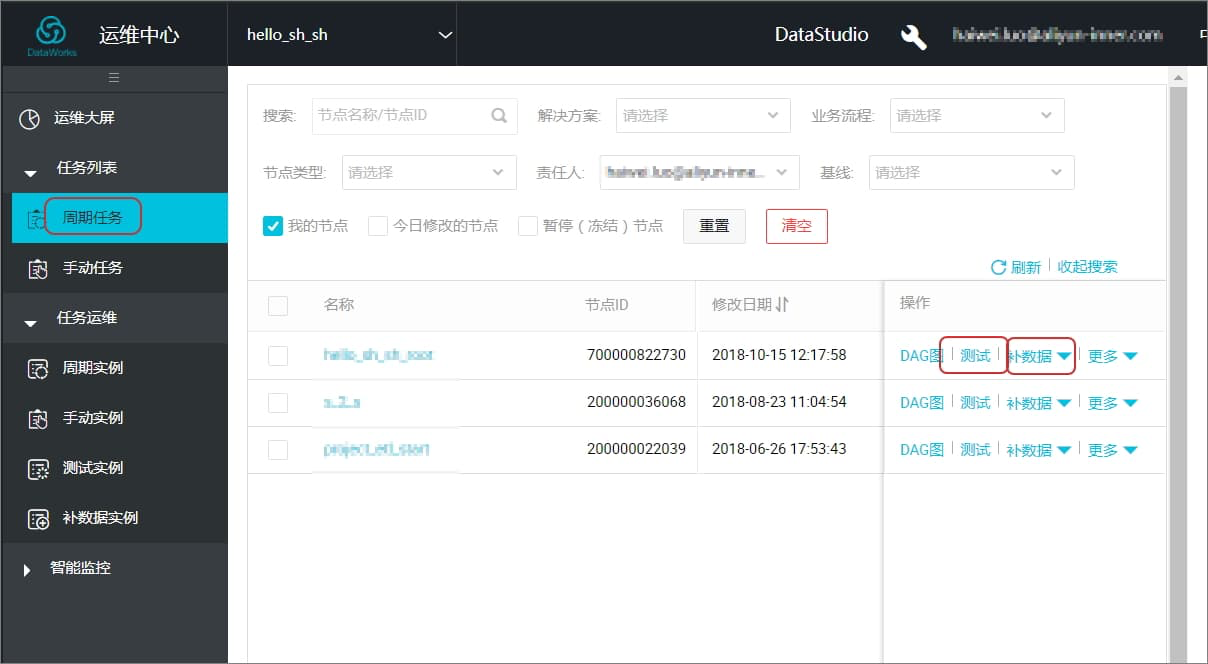
在DataWorks中,补数据操作主要支持周期任务,包括补当前节点及其下游节点。您可以创建数据表并导入原始数据,之后创建一个补充数据节点,通过编写SQL补充数据程序实现数据的读取、转换和补充等操作。同时,补数据功能不仅支持补充历史一段时间区间的数据,还可以选择需要补未来一段时间的数据。
具体来说,您可以按照以下步骤进行数据补偿:首先,登录DataWorks控制台并进入目标项目;其次,进入数据开发模块;然后,找到需要补数据的任务。此外,您还可以在运维中心查看发布至生产环境的任务,执行测试、补数据等相关运维操作。
需要注意的是,使用限制中规定仅华南1(深圳)、中东东部 1(迪拜)地域支持周期任务使用高级模式进行补数据。实例在过期后(30天左右)平台将自动删除,如果任务不需要再运行,可以选择冻结实例。公共调度资源组实例保留一个月(30天)、日志保留一周(7天),独享调度资源组任务实例、日志保留一个月(30天)。运行完成状态的实例,当日志大于3M时,平台会每天定时清理。
在DataWorks中,您可以使用以下方法来补数据:
DataWorks中的补数据操作,在数据缺失或不完整时进行数据补充,以确保数据的完整性和准确性。以下是DataWorks中补数据的常用方法:
DataWorks中可以通过创建补数节点和配置补数节点来补数据。创建补数节点可以通过以下步骤完成:
以上就是DataWorks中补数据的基本步骤。希望对您有所帮助。
补数据https://help.aliyun.com/zh/dataworks/support/data-backfilling?spm=a2c4g.11186623.0.i39
补数据功能说明
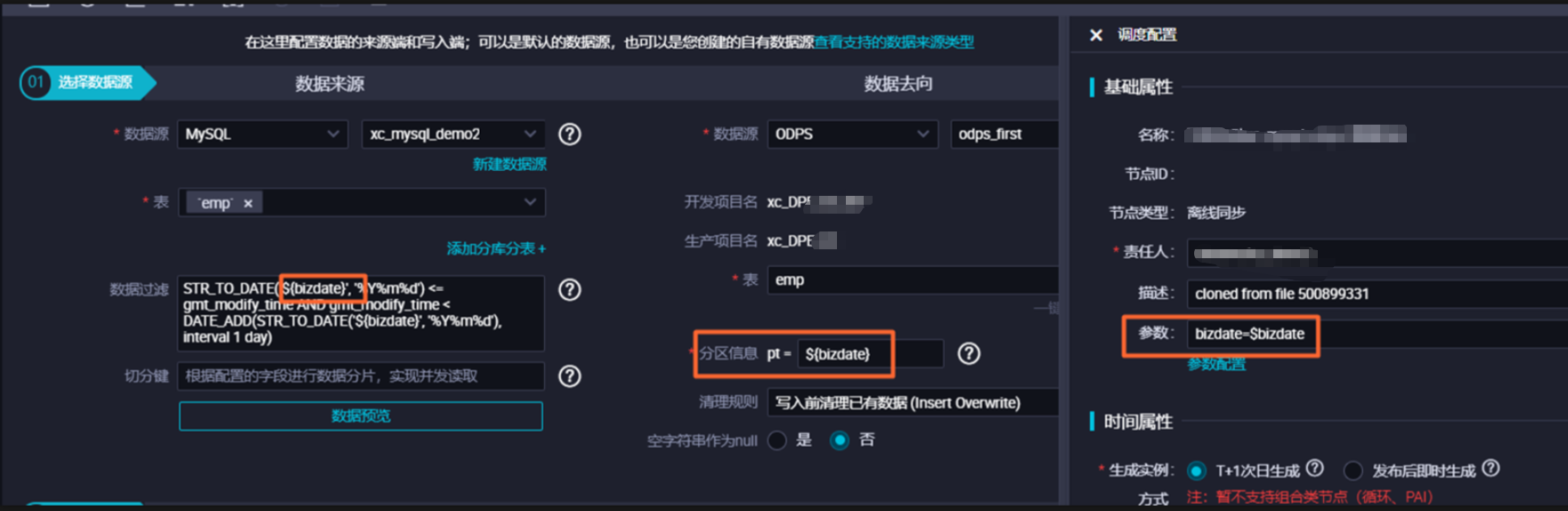
补数据支持补历史一段时间区间的数据或者需要补未来一段时间的数据时,可以选择补数据功能。节点使用的调度参数会根据补数据选择的业务时间自动替换为对应的值。将MySQL增量数据写入MaxCompute对应的时间分区中的示例如下。
为什么小时分钟任务补数据选择了并行但实际不生效?
问题现象
小时分钟任务补数据选择了并行但实际不生效。
产生原因
补数据并行控制是,补一段以天为维度的业务日期区间的数据以及几天的实例是否同时执行。此功能不控制小时、分钟任务当天的所有实例是否并发执行,当天小时分钟任务的实例是否并发执行与您小时分钟任务是否设置了自依赖有关。自依赖使用说明,请参见场景2:依赖上一周期的结果时,如何配置调度依赖。
解决措施
选择不并行,一个补数据实例下的多个业务日期串行执行,即上一个业务日期的补数据实例执行完,下一个业务日期的补数据实例才会执行。
选择并行,您可以设置同时使用2组、3组、4组或5组等多个补数据实例进行补数据,即多个补数据实例下有多个业务日期并行执行。
实时场景:假设小时、分钟节点选择补一个星期数据。
如果小时、分钟节点设置了自依赖,那么小时、分钟节点每天的实例会一个一个执行。
如果小时节点任务没有设置自依赖,那么小时、分钟节点每天的实例一块执行。
在DataWorks中,补数据的方法主要有以下几种:
重跑任务并修正数据:如果数据问题只是由于任务执行失败或产生了错误数据,可以重新运行任务并修正数据。在DataWorks中,可以通过重试或重新调度任务来实现。
通过脚本或程序进行数据修复:如果需要批量修改或更新数据,可以使用脚本或程序的方式来进行数据修复。在DataWorks中,可以新建一个ODPS SQL节点,然后编写相应的SQL语句或Java程序进行数据修复。
手动导入修复数据:如果只需要修复少量数据,也可以手动导入数据进行修复。在DataWorks中,可以直接在ODPS SQL节点中编写INSERT语句,并将需要修复的数据手动导入到表中。
使用ODPS Console进行数据修复:ODPS Console是MaxCompute提供的Web界面控制台,可以用于管理、调度和监控MaxCompute资源和任务。在ODPS Console中,可以通过上传文件或使用Web IDE等功能进行数据修复。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。