
文档智能这两个限制,后期会去掉吗,或者有其他方法识别超过20m并且文档字数超大的文档呢?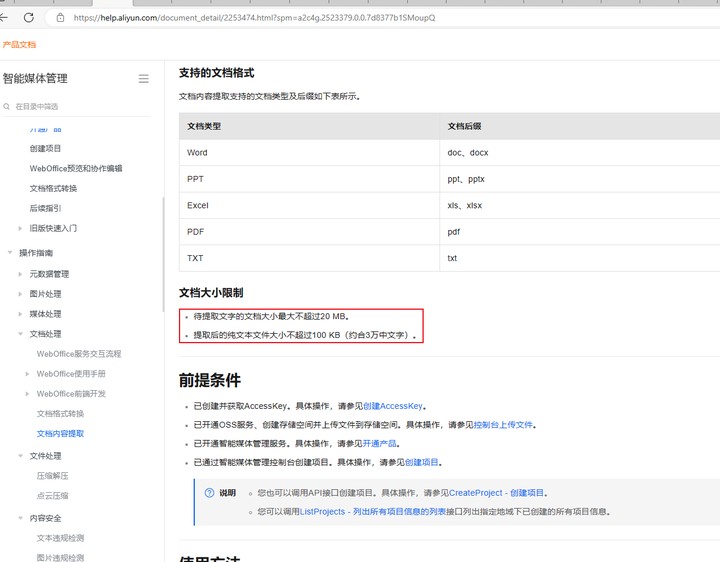
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据现有知识库资料,文档智能目前对文件大小和文档字数有一定的限制,但这些限制并非完全不可调整或绕过。以下是针对您问题的详细解答:
文档智能各功能支持的文件大小限制可以根据用户需求进行调整。如果您的业务场景需要处理超过20MB的文件,建议直接联系阿里云技术支持团队。通过与技术团队沟通,您可以获得定制化的解决方案,以满足特定需求。
对于文档字数超大的情况,文档智能提供了以下几种可能的解决方案:
文档解析(大模型版)支持单个文档最大为1.5万页且不超过150MB的PDF或Word文件。如果您的文档超出此范围,可以通过将文档拆分为多个较小的子文档(如按章节或段落拆分),分别上传并处理。处理完成后,再将结果合并。
文档解析(大模型版)提供异步提交服务接口(SubmitDocParserJob 和 SubmitDocParserJobAdvance),支持本地文件和URL文件两种方式上传。对于较大的文档,建议使用异步处理方式,避免因文件过大导致的处理失败或超时问题。
如果文档过大且无法直接上传,可以先使用“PDF转图片”功能,将PDF逐页转换为图片格式,然后分批上传图片进行处理。该功能支持最大100MB的PDF文档,并能高效还原文档内容和版式样式。
如果您经常需要处理超大文档,可以考虑基于文档智能的自定义模型功能,针对特定场景进行优化。例如: - 长文档信息抽取:适用于文档样式较为简单或复杂的场景,支持PDF和图片格式。建议准备至少50张训练数据以获得较好的识别效果。 - 表格信息抽取:适用于结构化信息抽取的场景,支持列表型和键值对型表格。建议准备至少20张训练数据。
如果您当前的需求无法通过上述方法解决,建议联系阿里云技术支持团队,获取更高级别的定制化服务。同时,持续关注文档智能的功能更新,未来可能会进一步放宽文件大小和文档长度的限制。
希望以上信息能够帮助您解决问题!如有其他疑问,请随时联系我们。
