
DataWorks中oss如何上传json数据到odps?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中创建一个新的数据源,并选择OSS作为数据源类型。
在创建数据源时,需要填写OSS的Access Key ID、Access Key Secret以及Bucket名称等信息。
在创建数据源后,可以在DataWorks的工作流中使用OSS数据源来读取或写入数据。
如果需要将json数据上传到OSS,可以使用DataWorks中的文件操作任务。在文件操作任务中,可以选择将本地文件上传到OSS。
在DataWorks中创建一个任务,选择“OSS”作为源数据,并选择“ODPS”作为目标数据。
在任务参数配置页面中,填写任务名称、描述、源数据参数(如OSS Bucket名称、Object名称等)和目标数据参数(如ODPS数据库名称、表名称等)。
在任务配置页面中,编写SQL脚本,用于将JSON数据转换为ODPS支持的格式。
在任务配置页面中,设置任务调度,定期执行JSON数据的上传任务。
在DataWorks中,可以使用数据集成功能将JSON数据从OSS(Object Storage Service)上传到ODPS(MaxCompute)。以下是一种常见的方法:
配置数据源:在DataWorks中配置OSS和ODPS的数据源连接。确保您具有正确的权限来访问和操作这两个数据源。
创建数据集成任务:使用DataWorks的数据集成功能,创建一个新的数据集成任务。
配置源端连接:在任务中配置源端连接,选择OSS作为源数据源,并提供OSS的Endpoint、AccessKeyId、AccessKeySecret等信息。
配置目标端连接:在任务中配置目标端连接,选择ODPS作为目标数据源,并提供ODPS的Endpoint、AccessKeyId、AccessKeySecret等信息。
设置数据同步规则:在任务中设置数据同步规则,具体包括文件路径、格式、字段映射等。对于JSON数据,可以选择适当的格式(如JSON File),并映射JSON字段到ODPS表的对应字段。
调度和执行任务:根据需求配置任务的调度策略和触发器,以便定期或实时地执行数据同步任务。
一、打开OSS,上传文件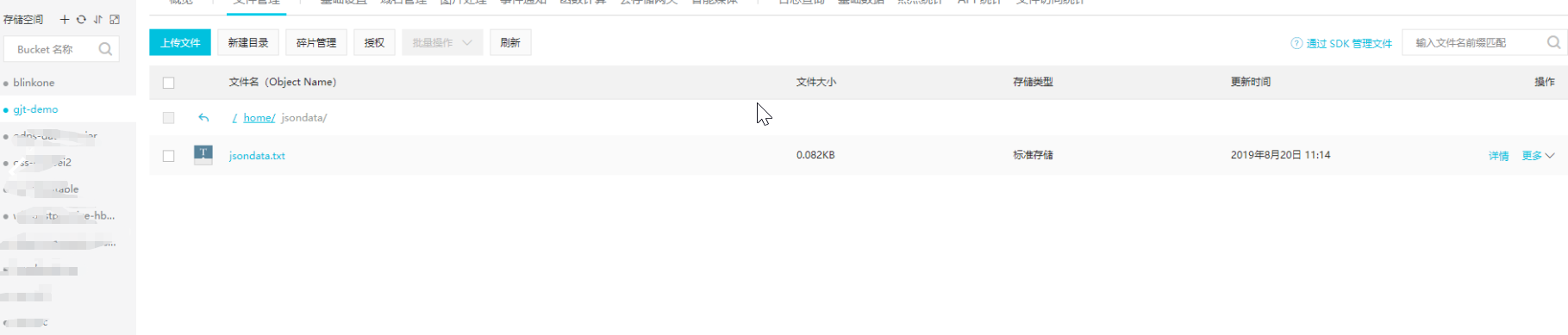
{"id":5644228109524316032,"sourceType":1}
{"id":-736866360508848202,"sourceType":3}
二、登录DataWorks,建立外部表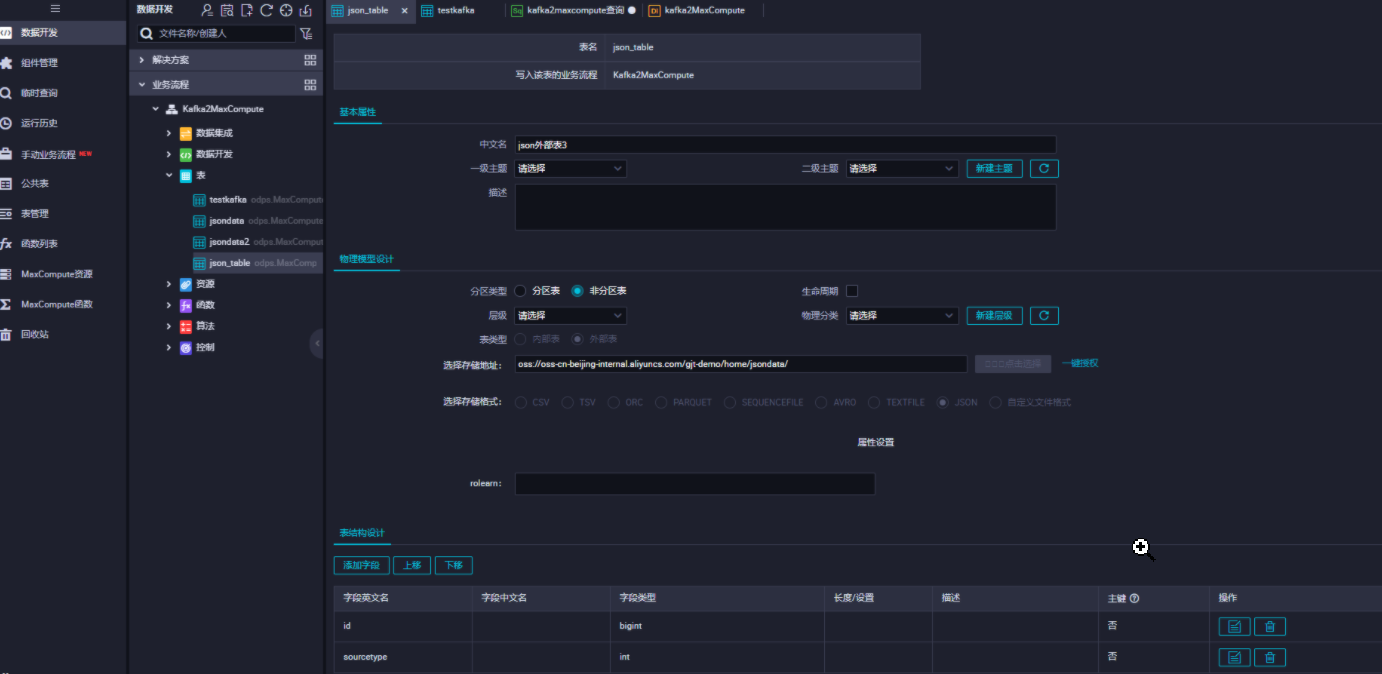
三、建立临时查询,查看数据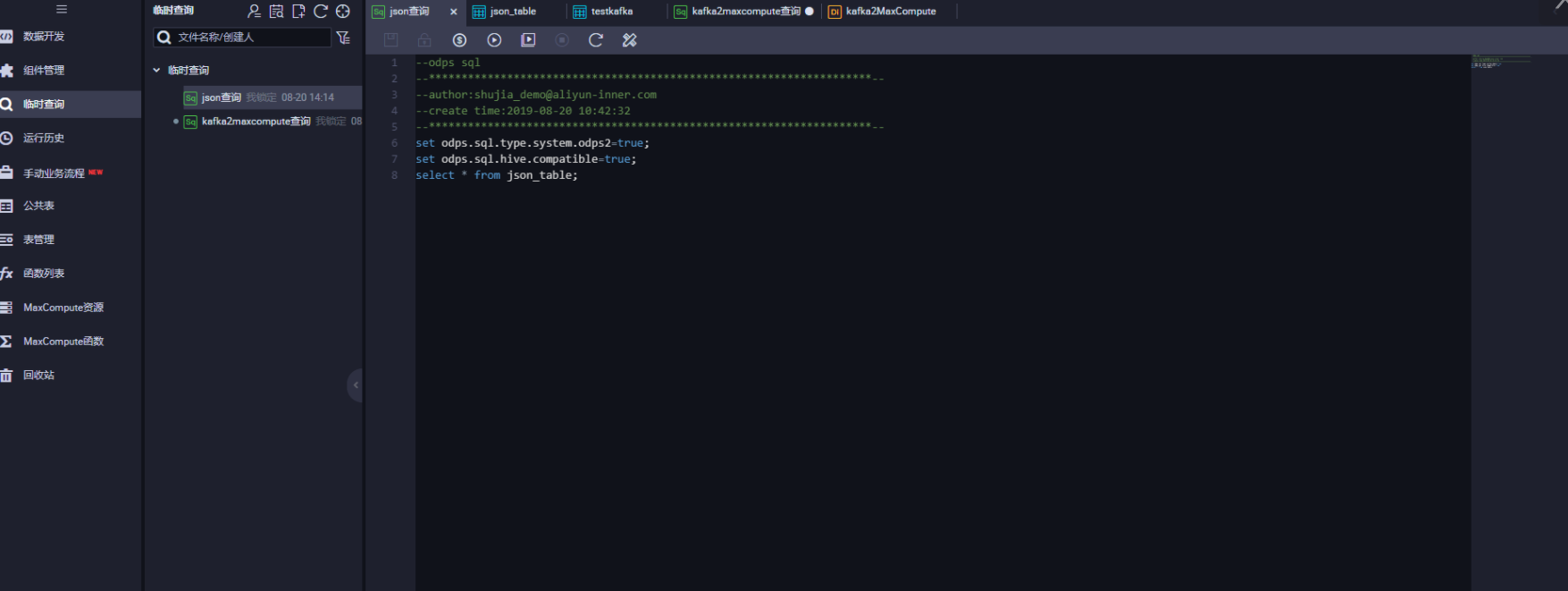
set odps.sql.type.system.odps2=true;
set odps.sql.hive.compatible=true;
select * from json_table;
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在DataWorks中,可以通过创建Data Source和Job,将OSS中的JSON数据上传到ODPS中。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


