
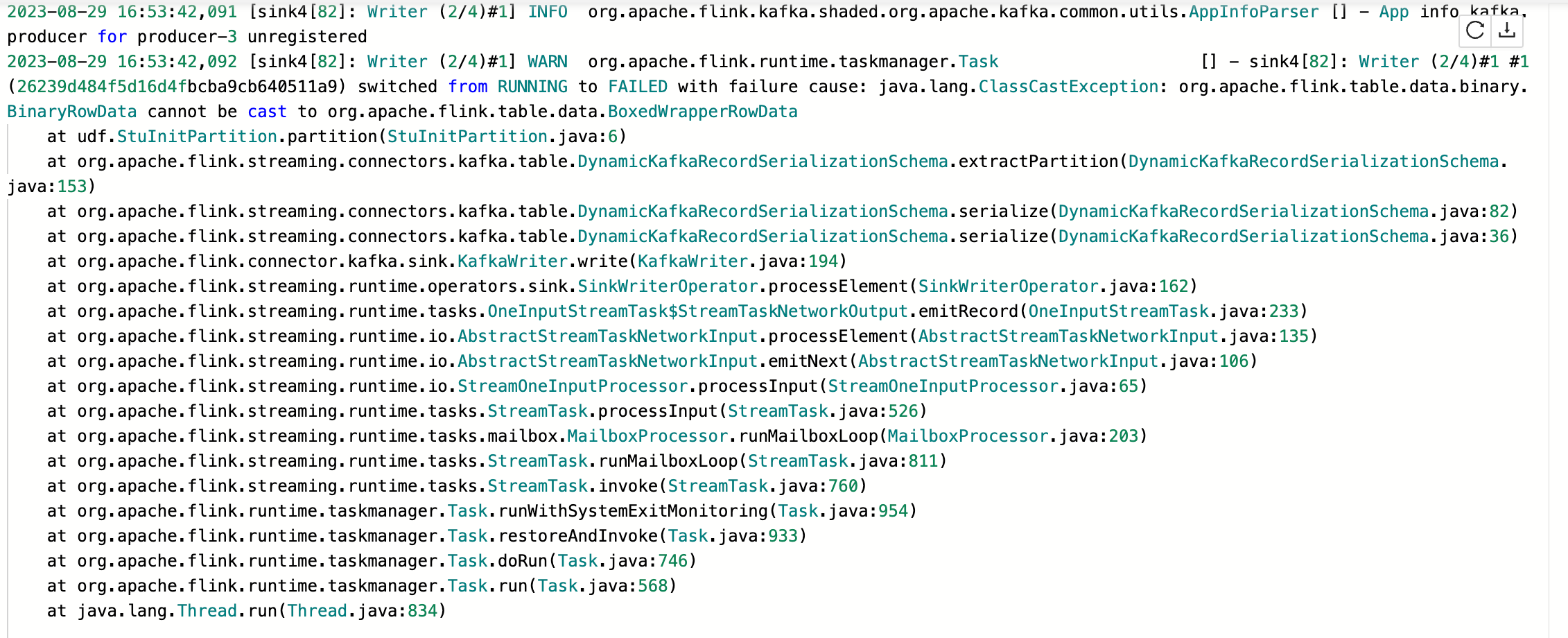
Flink CDC我自定义了一个flink SQL的Kafka分区器,在写入的时候会报类型转换异常,有遇到这个问题的吗?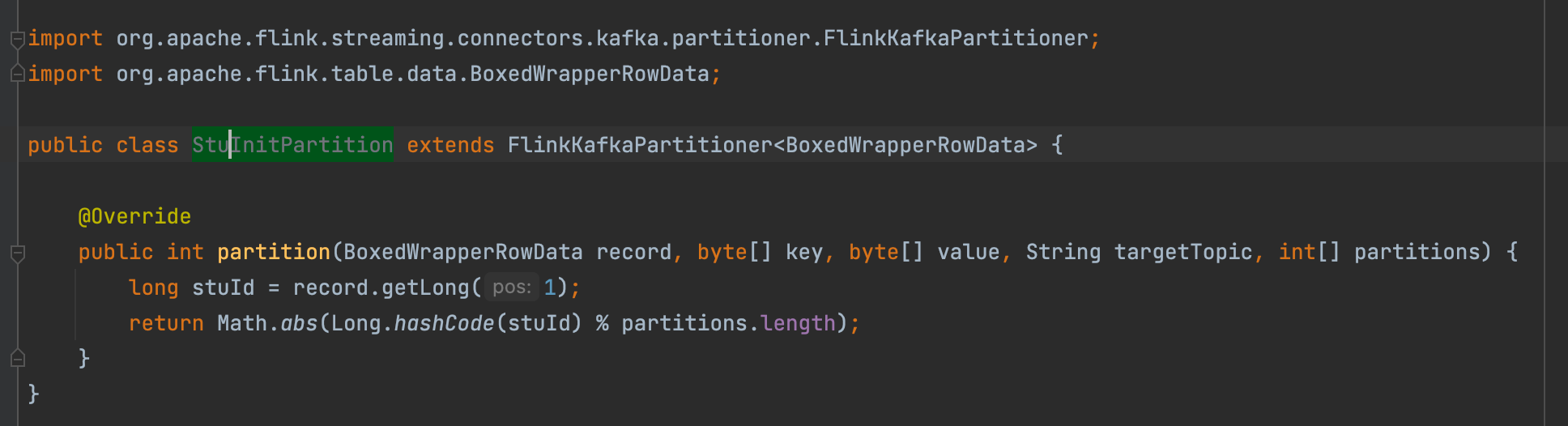
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC自定义Kafka分区器时,如果遇到类型转换异常的问题,可能是由于以下几个原因导致的。以下是详细的分析和解决方案:
Flink SQL中声明的数据类型与实际写入Kafka的数据类型可能存在不一致。例如,您在DDL中声明的字段类型可能比实际数据的类型更宽泛或不兼容。
DOUBLE vs BIGINT),Flink会自动解析为声明的类型。STRING vs ROW),会导致类型转换异常。此时需要重新启动作业并声明准确的类型。ROW、ARRAY、MAP)处理为STRING。如果您的数据包含复杂类型,请确保分区器能够正确处理这些类型。自定义分区器需要继承FlinkKafkaPartitioner,并在实现中正确处理数据类型。如果分区器逻辑中未正确处理某些字段类型,可能会导致类型转换异常。
partition方法,并正确处理了输入数据的类型。调试分区器:
public class MyPartitioner extends FlinkKafkaPartitioner<Row> {
@Override
public int partition(Row record, byte[] key, byte[] value, String targetTopic, int[] partitions) {
// 打印调试信息
System.out.println("Record: " + record);
System.out.println("Key type: " + (key != null ? key.getClass().getName() : "null"));
System.out.println("Value type: " + (value != null ? value.getClass().getName() : "null"));
// 自定义分区逻辑
return record.getField(0).hashCode() % partitions.length;
}
}
Flink CDC读取的数据可能包含特殊格式(如UPDATE_BEFORE和UPDATE_AFTER),这些数据在写入Kafka时会被转换为DELETE和INSERT类型。如果分区器未正确处理这些变更事件,也可能导致类型转换异常。
DELETE事件(即value为空的消息)。table.exec.source.cdc-events-duplicate=true,并在源表上定义主键以去重。如果Kafka中存储的数据格式与Flink SQL中定义的Schema不一致,也可能导致类型转换异常。
kafka-console-consumer)查看实际写入Kafka的消息内容,确认是否存在格式或类型问题。server-time-zone参数与MySQL服务器时区一致,否则可能导致时间戳解析错误。通过以上分析,您可以按照以下步骤排查和解决问题: 1. 检查DDL定义,确保字段类型与实际数据一致。 2. 调试自定义分区器,确保其能够正确处理输入数据的类型。 3. 检查CDC数据格式,确保分区器能够处理变更事件。 4. 验证Kafka Schema,确保与Flink SQL定义一致。 5. 检查时区和网络配置,排除其他潜在问题。
如果问题仍未解决,建议提供具体的异常堆栈信息和相关配置,以便进一步分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

