
文字识别OCR 我这个模板有中英文的 而且不是在一个高度 这个钢卷号识别不了怎么解决?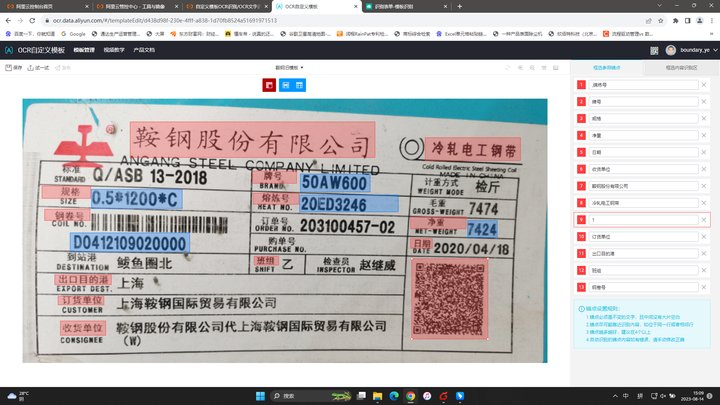
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果您的文字识别OCR模板包含中文和英文,并且这些文本位于不同的高度位置,导致OCR无法准确识别钢卷号,可以尝试以下方法来解决这个问题:
调整感兴趣区域(ROI):通过指定感兴趣区域,将OCR的识别范围限定在钢卷号所在的位置附近。可以根据钢卷号所处的相对位置和大小,调整ROI的坐标参数,以便更好地识别钢卷号。
调整文字识别参数:OCR服务通常提供了一些可调节的参数,例如文字大小、字体类型等。您可以尝试调整这些参数,以适应钢卷号的特定样式。尝试使用较大的文字大小,或选择与钢卷号相似的字体类型,可以提高识别的准确性。
图像预处理:对于OCR难以识别的文字,可以尝试对图像进行预处理操作,如增强对比度、降噪、调整亮度等。这些操作可以改善图像质量,使OCR能够更好地识别钢卷号。
尝试多次识别:如果单次识别无法准确识别钢卷号,可以尝试多次进行OCR识别,并选择最匹配的结果。通过尝试不同的参数设置、图像处理和模型调整,可以提高钢卷号识别的准确性。
自定义模板:如果以上方法无法解决问题,您可以考虑使用OCR服务提供的自定义模板功能。通过自定义模板,您可以根据具体需求指定特定位置和样式的文本区域,以便更精确地识别钢卷号。
自定义KV模板是针对卡证、票据等固定版式的数据提供的一款定制化产品。用户仅需通过一张模板数据的可视化拖拉拽配置,无需进行数据标注和模型训练,即可实现相同版式数据的自定义结构化识别抽取。经过配置调优的模板识别准确率可达85%以上。
同时工具箱中还提供分类器管理工具与字段类型管理工具,支持用户通过同一接口完成不同版式数据的自动分类路由与高精度识别。
功能优势
低成本,仅需提供一张样图即可完成模板搭建,无需标注。
低门槛,通过拖拉拽可视化配置即可完成模板定义,无需二次开发。
高效率,3-5分钟即可完成一个模板的配置。
https://help.aliyun.com/document_detail/603348.html?spm=a2c4g.442245.0.i3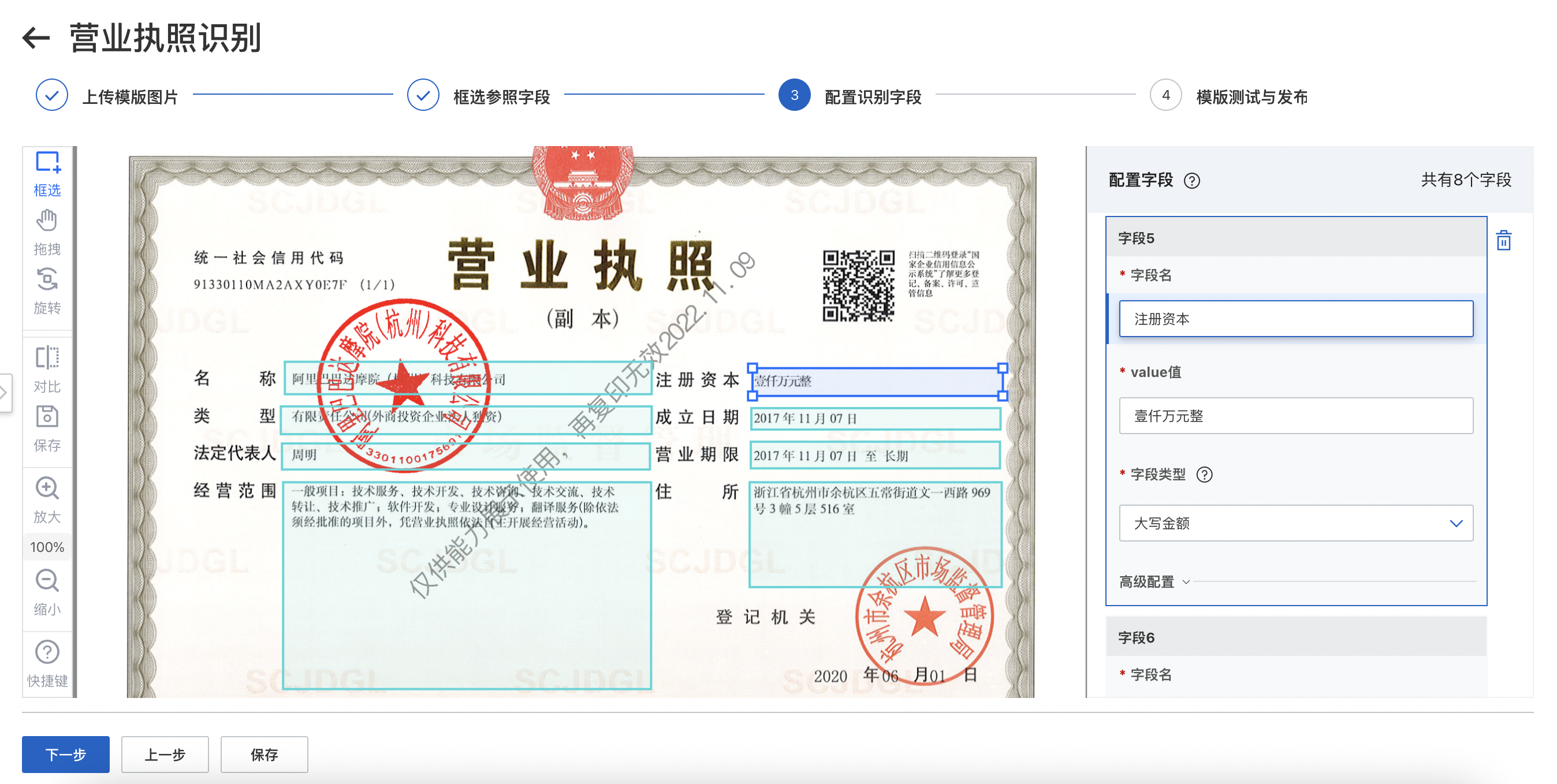
针对钢卷号识别问题,如果阿里云的文字识别OCR无法准确识别中英文且不在同一高度的模板,您可以尝试以下方法来解决:
图片预处理:在使用OCR服务之前,可以对图片进行预处理,包括调整图像的对比度、亮度、清晰度等,以提高识别效果。可以尝试先对图片进行切割,将中英文部分分开,并分别进行预处理。
文本区域检测:使用图像处理技术,如边缘检测、轮廓检测等,找到并分割出中英文文本的区域,然后分别对这两个区域进行识别。该方法需要先确定中英文文本的位置信息,可能需要一些手动操作和调试。
自定义模型:如果钢卷号识别对于业务非常重要,可以考虑自定义训练一个模型,采用机器学习或深度学习的方法来进行识别。您可以收集钢卷号的样本数据,并使用相关的模型训练算法进行训练,以提高准确性和适应性。
其他OCR服务供应商:如果阿里云的OCR服务无法满足需求,您还可以尝试其他OCR服务供应商的API,以获得更好的识别效果。不同供应商的OCR技术可能有所差异,可以进行比较和评估。
另外,如果您的业务需求中存在特定的约束或规则,例如钢卷号的格式和字符特征,您可以将这些信息提供给OCR服务供应商,以帮助提高识别准确性。同时,您也可以向阿里云反馈该问题,以便他们改进和优化OCR服务。


