
"Flink CDC中世界是 20多万的数据,为啥落库的时候只有 10多万?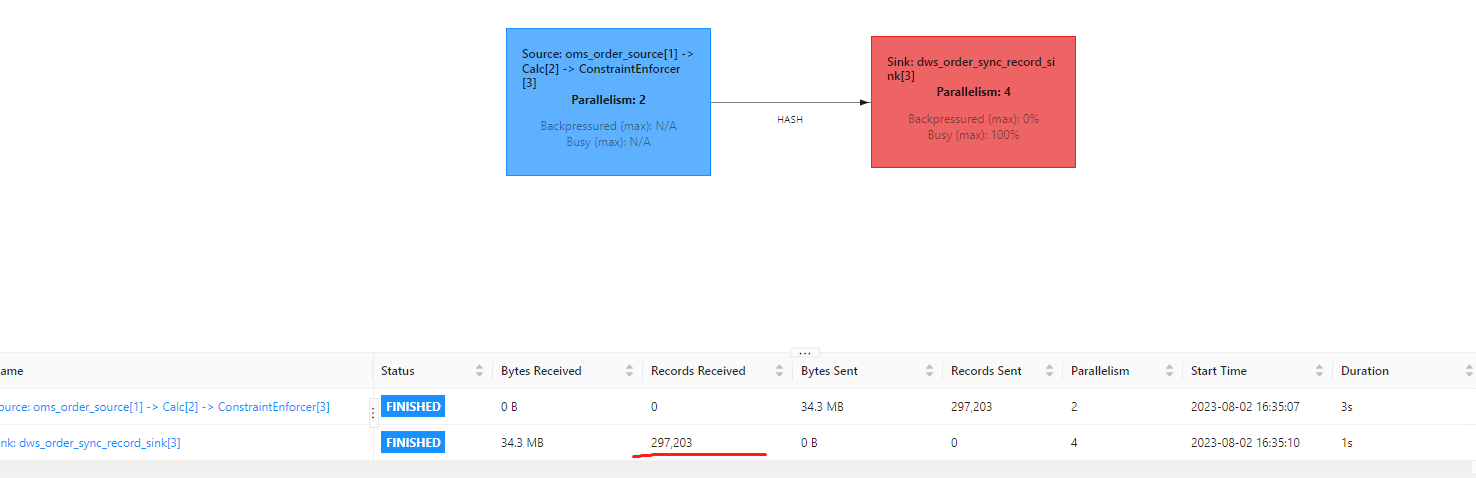
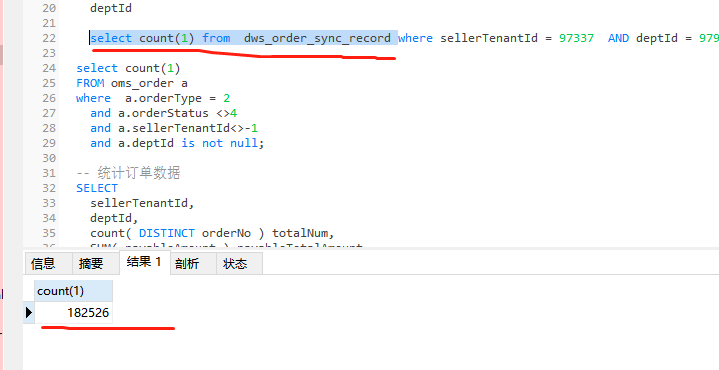
批任务,我使用mysql 查询的数量都一致的,就是 flink 落库的时候不对。简单的etl 使用sql ,但是测试还是有问题。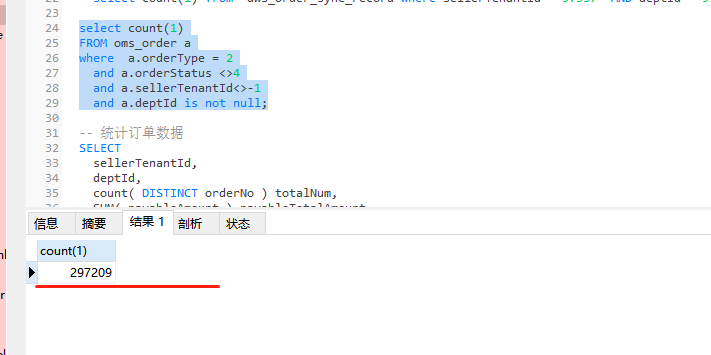
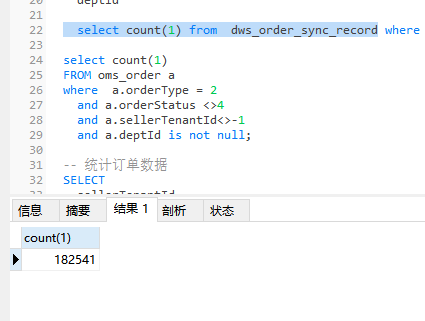
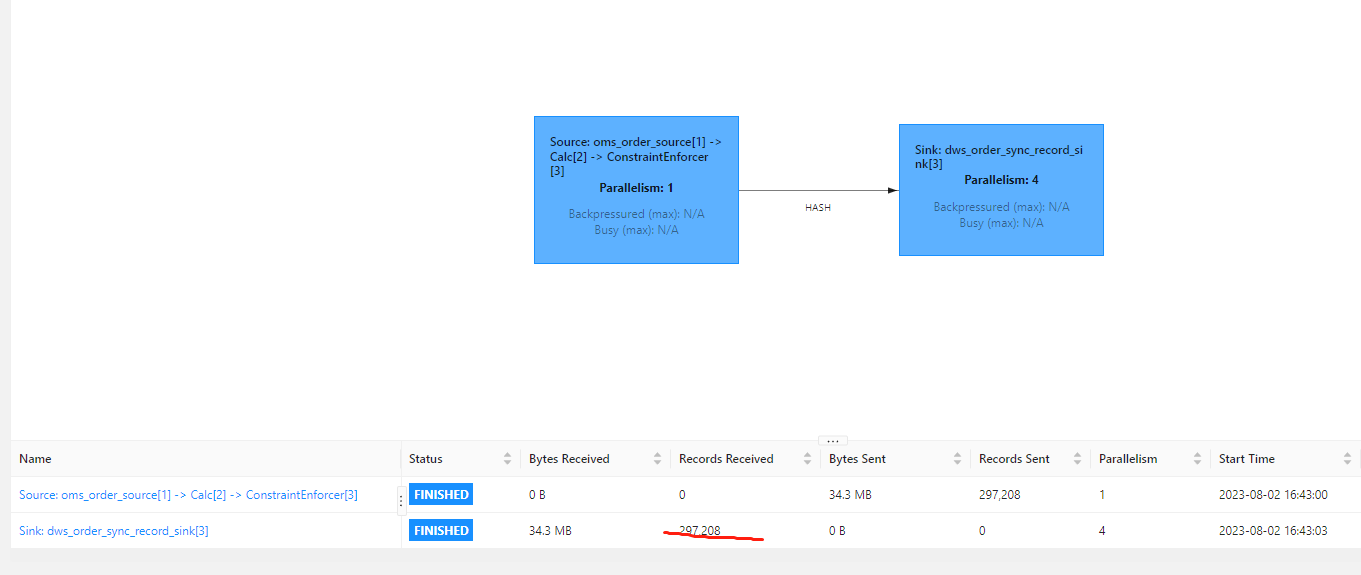
flink 说的是流批一体,不想弄那么中间件。
"
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果在使用 Flink CDC 进行数据同步时,源数据有 20 多万条记录,但最终只有 10 多万条记录被成功写入目标数据库,可能有以下几个可能的原因:
过滤条件:检查你的 Flink CDC 应用程序是否设置了过滤条件,导致某些记录被过滤掉而没有写入目标数据库。确保过滤条件正确设置,以便包含所有需要同步的数据。
数据源问题:检查源数据的完整性和准确性。可能是源数据中存在重复记录、缺失记录或其他数据问题导致最终写入目标数据库的记录数量不符合预期。
数据转换或处理错误:如果你在 Flink CDC 应用程序中对数据进行了转换或处理操作,错误的处理逻辑可能导致数据丢失或数量减少。检查你的数据转换或处理逻辑,确保它们正确地处理源数据并生成正确的目标数据。
数据写入失败:在数据写入目标数据库时,可能发生写入失败的情况。这可能是由于数据库连接问题、目标表定义不匹配或其他写入错误导致的。检查你的目标数据库的配置和表定义,确保它们与写入操作相匹配,并查看日志或错误信息以获取更多关于写入失败的信息。
并发或同步延迟:如果你的 Flink CDC 应用程序使用并发处理或存在同步延迟,可能会导致最终写入目标数据库的记录数量不符合预期。在这种情况下,你可以调整并发度或处理延迟的配置,以满足你的需求。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


