
机器学习PAI kv特征的问题查了下,应该还是编码问题,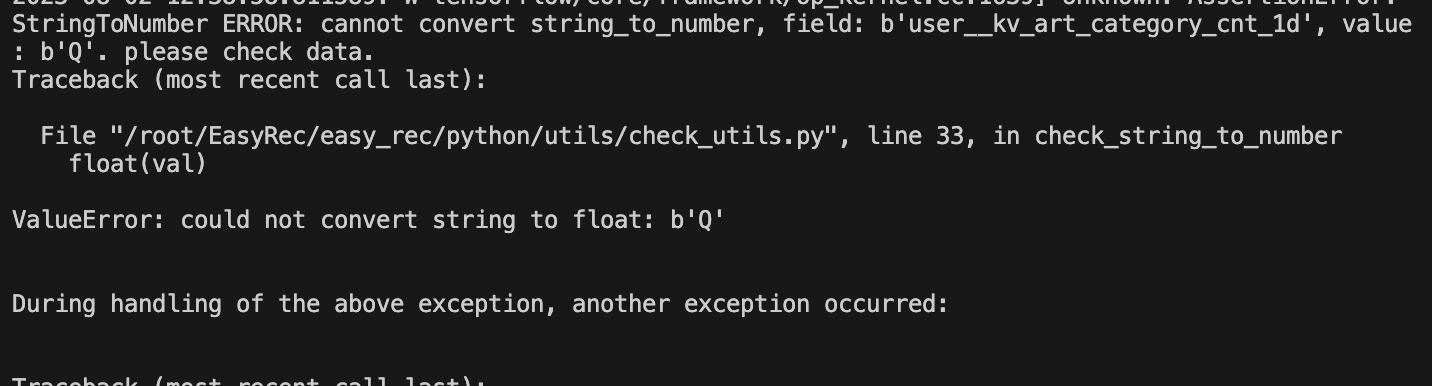
于是在odps_input_v3的时候,就decode解码一遍?负采样的的gl,values.py 最后就这样解决的,从odps down 数据处理是不是会有编码问题啊?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
面是一些与编码相关的常见情况和解决方法:
字符串编码:如果键值特征中包含字符串类型的数据,可能需要将其编码为数值或分类变量才能在机器学习模型中使用。常见的编码方法包括独热编码(One-Hot Encoding)、标签编码(Label Encoding)等。独热编码将每个类别转换为二进制向量,而标签编码将每个类别映射为一个整数标签。
数值类型:如果键值特征是数值类型的数据,通常无需进行额外的编码处理。你可以直接将这些数值特征作为输入供给模型使用。
缺失值处理:键值特征中可能存在缺失值,需要进行适当的处理。一种常见的方法是使用特定的值(如0或平均值)填充缺失值,或者使用算法进行缺失值的估计和填补。
文本数据:如果键值特征包含文本类型的数据,你可能需要将其进行分词、去除停用词、进行词干化等文本预处理操作。然后,可以使用词袋模型(Bag-of-Words)或词嵌入模型(如Word2Vec或BERT)来将文本转换为数值特征。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。


