
Flink的tidb 支持cdc么?
Flink的tidb 支持cdc么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
https://help.aliyun.com/zh/flink/videos/flink-cdc-technology?spm=a2c4g.454036.0.i8
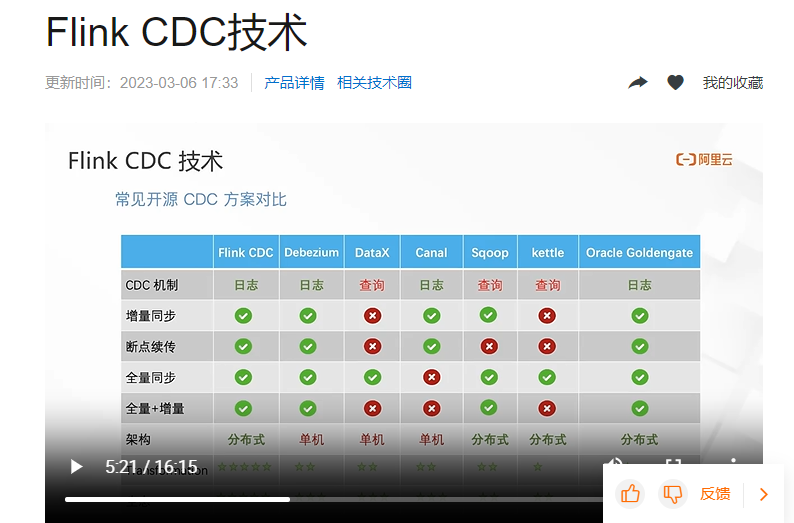
Flink CDC作业失败后能不能彻底退出,而不是重启?
MySQL/Hologres CDC源表不支持窗口函数,如何实现类似每分钟聚合统计的需求?
MySQL CDC表只能作为Source吗?
MySQL CDC使用table-name正则表达式不能解析逗号,怎么办?
作业重启时,MySQL CDC源表会从作业停止时的位置消费,还是从作业配置的位置重新消费?
MySQL CDC源表如何工作,会对数据库造成什么影响?
如何跳过Snapshot阶段,只从变更数据开始读取?
https://help.aliyun.com/zh/flink/support/faq-about-cdc?spm=a2c4g.11186623.0.0.b8827d2bkJpD3e#concept-2273621 2023-08-08 18:25:10赞同 展开评论
2023-08-08 18:25:10赞同 展开评论 -
十年摸盘键,代码未曾试。 今日码示君,谁有上云事。
Flink CDC (CDC Connectors for Apache Flink®) 是 Apache Flink® 的一组 Source 连接器,支持从 MySQL,MariaDB, RDS MySQL,Aurora MySQL,PolarDB MySQL,PostgreSQL,Oracle,MongoDB,SqlServer,OceanBase,PolarDB-X,TiDB 等数据库中实时地读取存量历史数据和增量变更数据,用户既可以选择用户友好的 SQL API,也可以使用功能更为强大的 DataStream API。
具体参考:https://github.com/ververica/flink-cdc-connectors
Flink CDC 2.2 版本新增了 OceanBase CE,PolarDB-X,SqlServer,TiDB 四种数据源接入。其中新增 OceanBase CDC,SqlServer CDC,TiDB CDC 三个连接器,而 PolarDB-X 的支持则是通过对 MySQL CDC 连接器进行兼容适配实现。
TiDB是一款开源分布式关系型数据库,同时支持在线事务处理与在线分析处理。TiDB CDC 的原理是通过直接读取其底层 TiKV 存储中的全量数据和增量数据实现数据捕获,其中全量部分是通过按 key 划分 range 读取,增量部分使用 TiDB 提供的 CDC Client 获取增量变更数据。
具体参考: https://docs.pingcap.com/zh/tidb/stable
可以使用flink新发布的flink tidb cdc来实现从tidb快速同步数据到StarRocks。
有一位大数据基础架构开发工程师最近在 TiBigData 实现了一把 TiDB 的流批一体 HybirdSource,其主要思想是利用 TiKV 的快照机制,从 TiKV 里以批的方式读取 TiDB 的全量数据,然后在 Kafka 里以流的方式读取 TiDB CDC 的增量数据,最后全量加增量合成一张实时的流表。
可以参考原文来源: https://tidb.net/blog/ac226af1
有将 TiDB 中的数据,通过 TiCDC 导入到 Kafka 中,继而被 Flink 消费的案例。
2023-08-08 14:29:01赞同 1 展开评论 -
不支持,我们内置 connector 支持的轻易官网文档为准。https://help.aliyun.com/zh/flink/developer-reference/supported-connectors?spm=a2c4g.11186623.0.0.58b826f8Rlcy78 此回答整理自钉群“实时计算Flink产品交流群”
2023-08-08 12:27:42赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。