
麻烦问下PolarDB的dn的架构呢?就像这种 看到他的标签 分成了leader,follwer,logger和learner 
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
PolarDB 是阿里云的一种分布式关系型数据库服务,支持多种架构。在 PolarDB 中,DN(Data Node)是负责存储数据和处理查询请求的组件。DN 的架构可以包含以下角色: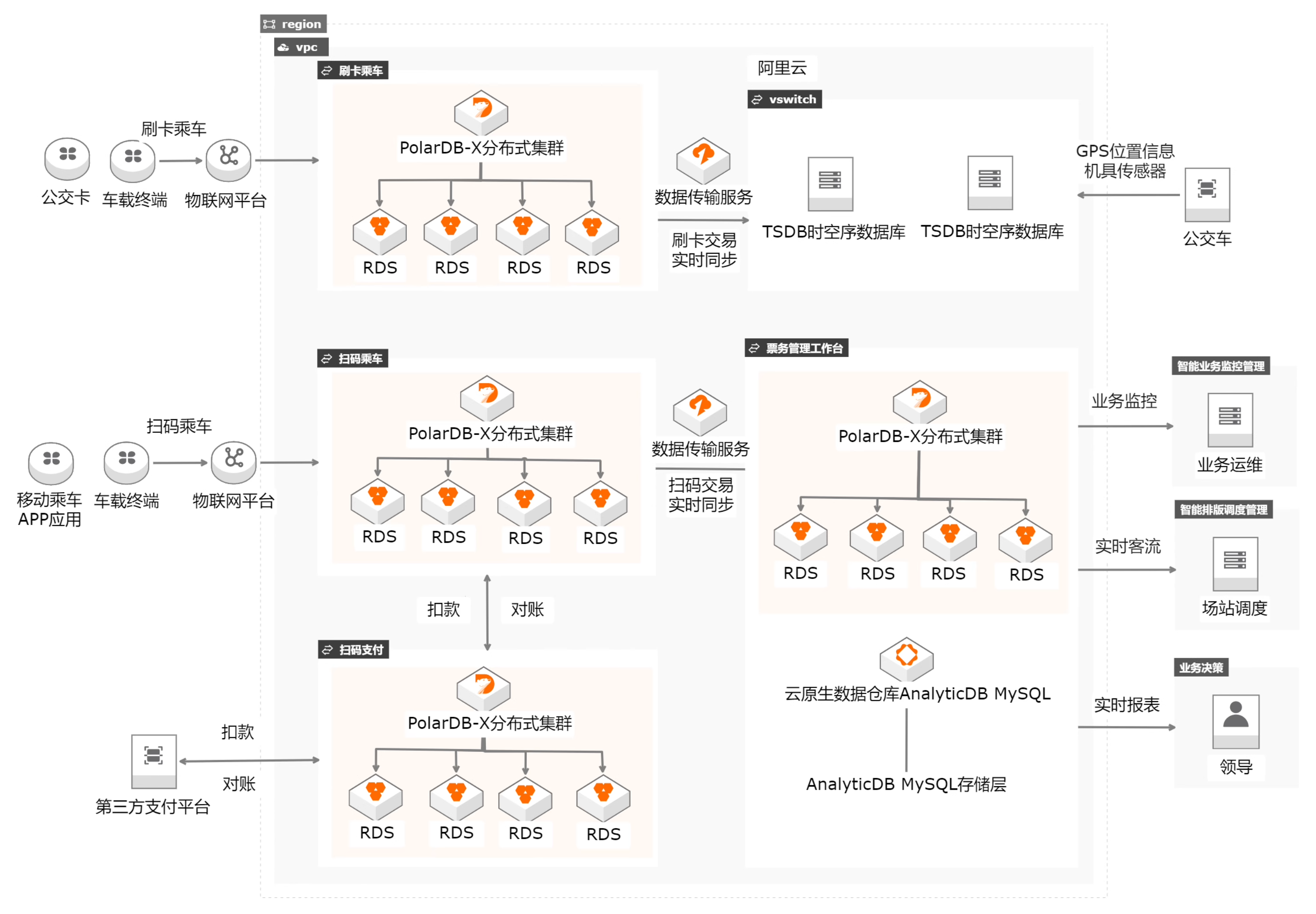
Leader:Leader 是一个 DN 节点,在集群中负责接收和处理写入请求,并将数据的变更同步给其他节点。Leader 负责维护数据的一致性。
Follower:Follower 是指那些与 Leader 具有相同数据副本的节点。Follower 负责接收和处理读取请求,并从 Leader 处获取最新的数据变更。Follower 通常用于提供高可用性和读取扩展性。
Logger:Logger 是负责将数据的变更写入日志文件的组件。当客户端提交事务时,Logger 将事务的变更写入日志,然后通知 Leader 和 Follower 进行相应的数据更新。
Learner:Learner 是类似于 Follower 的节点,但不参与读取请求的处理。Learner 用于备份数据或故障转移的过程中,以保证数据库的高可用性。
这些角色共同协作,实现了 PolarDB 的分布式架构,提供了高可用性、读写分离和数据冗余等功能。
需要注意的是,具体架构和角色可能会因 PolarDB 版本和配置而有所不同。PolarDB 在内部实现了一套复杂的分布式协议和算法,以确保数据的一致性和高效性。这些细节对于终端用户来说是透明的,可以专注于使用和管理数据库。
楼主你好,阿里云PolarDB的架构与传统的MySQL架构不同。PolarDB采用的是共享存储和分布式存储相结合的Hybrid架构,而且支持读写分离和自动分片。在PolarDB中,数据节点(DN)被分为三种角色:Primary、Secondary和Read Replica,其中Primary为主数据节点,Secondary为备份数据节点,Read Replica为只读数据节点。同时,PolarDB采用的是Quorum-based Replication机制,保证数据的高可用和一致性。因此,PolarDB的DN架构是多层次的,包含了多个组件,如Primary、Secondary、Learner、Logger和Proxy等。其中,Primary和Secondary之间通过Replication Protocol进行数据同步,Learner节点用于缓存Replication数据,并在需要时将数据合并到Secondary节点中,Logger记录Primary和Secondary之间的Replication状态,而Proxy则负责路由请求。总体来说,PolarDB的DN架构比较复杂,但是可以提供较高的性能和可用性。
PolarDB 的数据节点(Data Node,简称 DN)在架构上确实分为不同的角色,包括 leader、follower、logger 和 learner。这些角色在 PolarDB 中协同工作,以确保数据的一致性和可用性。下面是各个角色在 PolarDB 架构中的作用:
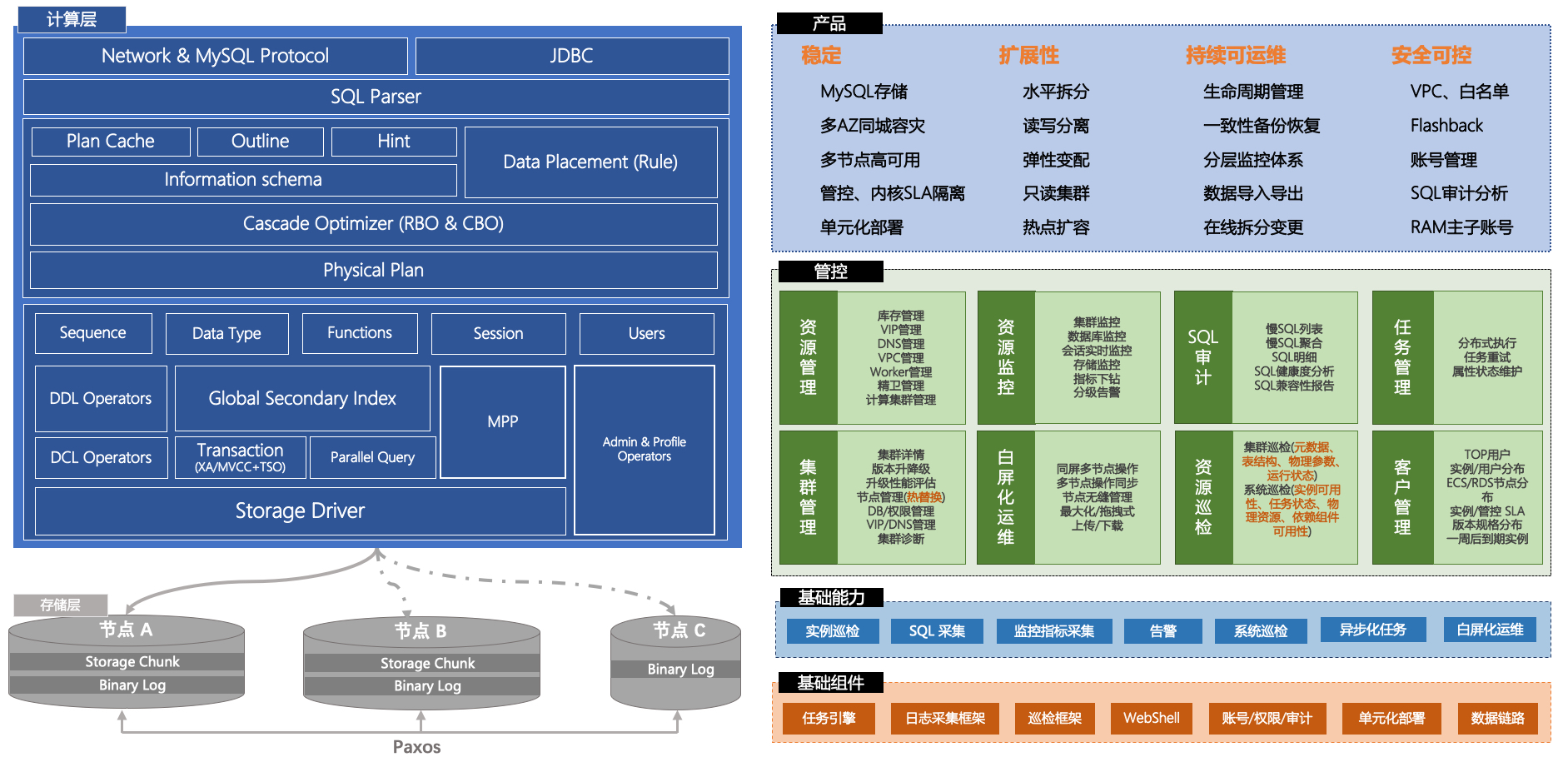
存储节点 (Data Node,DN),主要提供数据存储引擎,基于多数派Paxos共识协议提供高可靠存储、分布式事务的MVCC多版本存储,另外提供计算下推能力满足分布式的计算下推要求(比如Project/Filter/Join/Agg等下推计算),可支持本地盘和共享存储。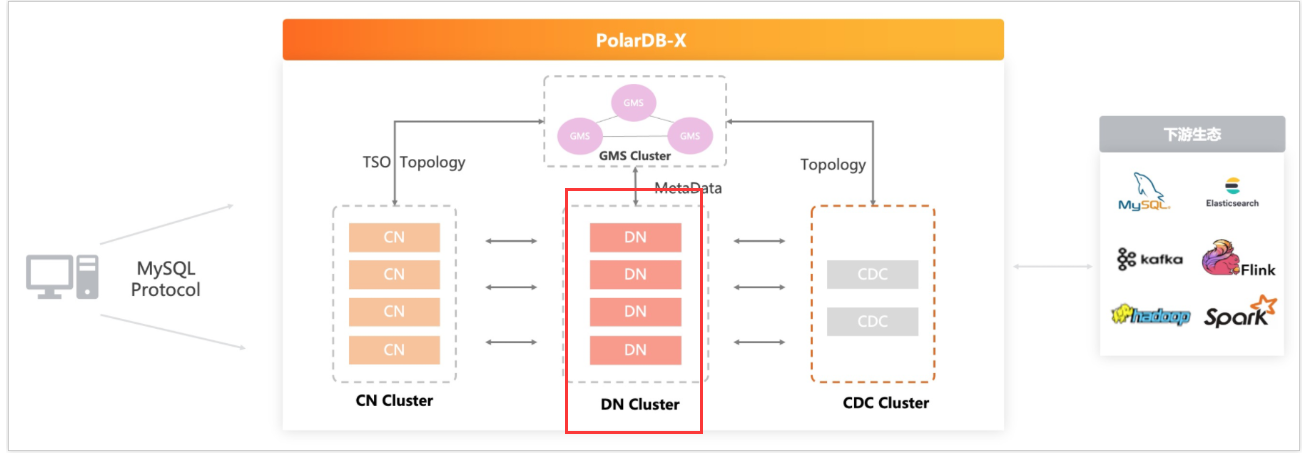
PolarDB-X将数据表以水平分区的方式,分布在多个存储节点(DN)中。数据分区方式由分区函数决定,PolarDB-X支持哈希(Hash)、范围(Range)等常用的分区函数。
以下图为例,shop库中的orders表根据每行数据的ID属性的哈希,被分区水平切分成orders_00~orders_11共计12个分区,均匀分布在4个数据节点上。对于用户来说,通常无需关心具体的数据分布,PolarDB-X的分布式SQL层将会自动完成查询路由、结果合并等。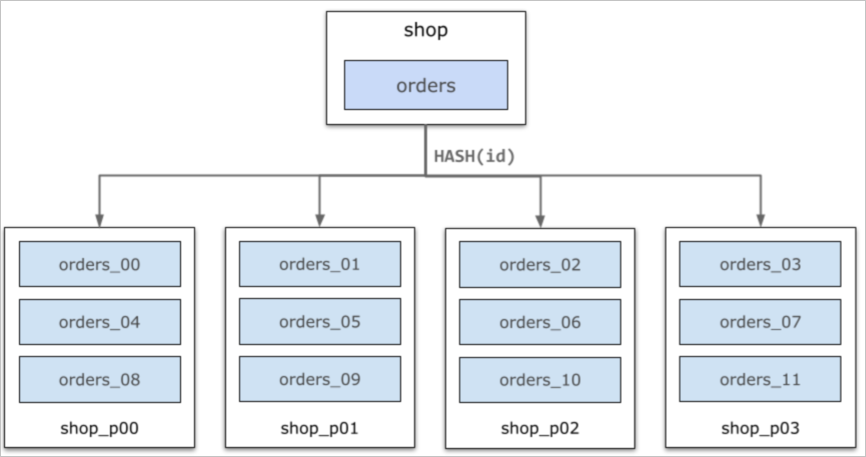
PolarDB-X通过引入中心授时节点(TSO),结合多版本并发控制(MVCC),保证读取到的一定是一致的快照,而不会读到转账事务的中间状态。如下图所示,提交事务时,计算节点(CN)执行事务时从TSO 获取到时间戳,随着数据一同提交到存储节点 (DN)多版本存储引擎上。读取时,如果查询操作的数据涉及多个分区,PolarDB-X首先会获取全局时钟作为读取版本,对每行数据的MVCC多版本进行可见性判断,确保读到全局一致的数据版本。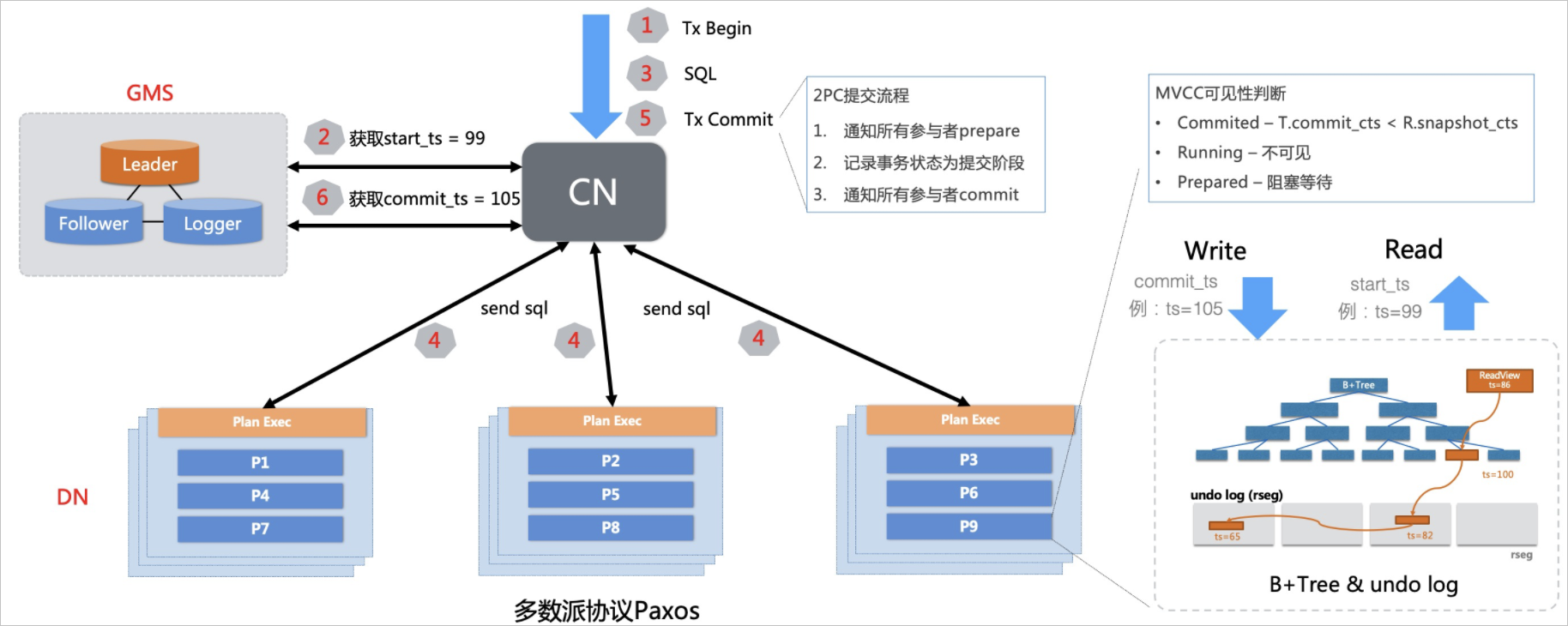
在 PolarDB 中,DN(Data Node)是一个核心组件,负责存储和处理数据。DN 之间采用了一种基于 Paxos 的分布式一致性协议来保证数据的一致性和可靠性。
PolarDB 的 DN 架构可以简单描述为以下几个角色:
Leader:每个 DN 集群中都有一个 Leader 节点,它负责接收并处理客户端的写入请求,并将写入操作复制到其他节点。Leader 节点也负责管理集群的元数据信息。
Follower:Follower 节点是 Leader 节点的备份节点,它们与 Leader 节点同步数据,并对客户端的读取请求进行响应。当 Leader 节点发生故障时,Follower 节点会选举出新的 Leader。
Logger:Logger 节点是负责记录所有的写入操作日志的节点。Logger 节点将写入操作日志异步地发送给 Follower 节点,以确保数据的持久性。
Learner:Learner 节点是加入集群的新节点,它们从 Leader 节点复制数据并学习集群状态。一旦 Learner 节点达到与 Leader 节点一致的状态,它们就可以成为 Follower 节点参与数据的读写操作。
通过以上角色的协作,PolarDB 实现了高性能、可靠的分布式数据库系统。Leader 节点负责写入请求,并将数据复制到 Follower 节点,Logger 节点记录写入操作日志,Learner 节点学习并同步数据状态。
这种架构设计可以提供高可用性、容灾能力和水平扩展性,同时保证数据的一致性和可靠性。
PolarDB的Data Node(DN)架构是分布式存储架构,其中包含了多个Data Node节点。每个Data Node节点负责存储和处理数据,并通过心跳和复制等机制与其他节点保持同步。
在PolarDB的DN架构中,每个节点都可以分为以下几个部分:
Leader节点:每个DN节点可以作为一个Leader节点,负责管理和控制该节点所在的分区。在PolarDB中,每个分区都有一个唯一的Leader节点,负责接收和处理该分区的写入请求。
Follower节点:每个DN节点可以作为一个Follower节点,负责跟随和复制Leader节点的状态。在PolarDB中,每个分区都有多个Follower节点,负责接收和处理该分区的写入请求,并将数据同步到其他节点上。
Logger节点:每个DN节点可以作为一个Logger节点,负责记录和存储该节点的日志信息。在PolarDB中,每个节点都有一个Logger节点,负责记录和存储该节点的日志信息,以便在故障排除和调试时使用。
Learner节点:每个DN节点可以作为一个Learner节点,负责学习和同步其他节点的数据。在PolarDB中,每个节点都有一个Learner节点,负责学习和同步其他节点的数据,以便在故障排除和调试时使用。
需要注意的是,PolarDB的DN架构是分布式存储架构,每个节点都可以独立地处理和存储数据,并通过心跳和复制等机制与其他节点保持同步。因此,PolarDB的DN架构具有高可用性和容错性,可以支持大规模的数据存储和处理。
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


