
polardb polarm的redo做主从是怎么做到的?redo放在了共享存储上?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,阿里云的 Polardb Polarm 是一种基于共享存储的分布式关系型数据库产品。在 Polarm 中,主库和备库之间的数据同步是通过 Polarm 自身的复制机制实现的。在 Polarm 中,redo 日志是存储在共享存储上的,主库写入 redo 日志时,备库会从共享存储中获取 redo 日志并进行同步,从而实现数据复制。
具体来说,Polarm 中的共享存储使用了分布式文件系统,可以在多个节点之间共享数据。在主库写入 redo 日志时,该日志会先写入共享存储的缓存中,然后再通过网络被传输到备库,备库接收到 redo 日志后也会将其写入共享存储上。这样主库和备库之间就可以共享 redo 日志了,从而实现了数据的同步。
需要注意的是,在使用 Polarm 进行主从复制时,如果主库出现故障,备库可以自动接替主库继续提供服务,这也是 Polarm 的一个重要特性。
PolarDB 是一款基于 InnoDB 存储引擎的分布式数据库,提供了高性能、高可用性和可扩展性的解决方案。在 PolarDB 中,主从复制是通过 InnoDB 存储引擎的 Redo 日志实现的。Redo 日志记录了所有对数据库的修改操作,包括事务的开始、事务的修改操作以及事务的提交等。在主从复制中,主库(Master)将 Redo 日志记录的操作复制到从库(Slave)上,从而实现数据的同步。
在 PolarDB 中,Redo 日志通常存储在共享存储上,这是因为共享存储可以提供高可用性和数据持久性。当主库发生故障时,可以从共享存储中恢复数据到新的主库,从而保证系统的持续运行。同时,将 Redo 日志存储在共享存储上也有助于简化管理和提高数据安全性。
在实现主从复制的过程中,PolarDB 使用了以下技术:
PolarDB的主从节点 共享同一个PolarFS(分布式文件系统),复用数据文件和log文件。
PolarDB采用基于redo log的异步物理复制的方式来实现主从节点的数据同步。
在主库有数据修改时, 主库更新后,相关的更新会通过redo log apply到只读库,具体的延迟时间与写入压力有关,一般在ms通过。这样实现了最终一致性 - 实现主库和只读库之间的最终数据一致。
为了解决最终一致性会出现的查询不一致,PolarDB利用自身物理复制速度快的优点,将查询发给已经更新了数据的只读节点。这样实现会话读一致性。
Primary和replica节点共享同一个PolarFS(分布式文件系统),复用数据文件和日志文件。Replica节点直接读取PFS上的redo Log,并进行解析,将其修改应用到自己buffer Pool中的page上,这样当用户的请求到达replica节点后,就可以访问到最新的数据了。同时replica和primary节点间也会保持RPC通信,用于同步replica当前日志的apply位点,以及ReadView等信息。
Standby节点部署在其他region中,拥有独立的PolarFS集群,拥有独立的数据和日志文件。Standby会向primary节点建立连接,用于读取primary节点上的redo log,并回发到standby节点,Standby节点会将redo log保存自己本地,并解析这些redo log,将其完全在自己的buffer pool中进行回放,并通过周期性的刷脏操作将数据持久化到磁盘,最终实现数据同步。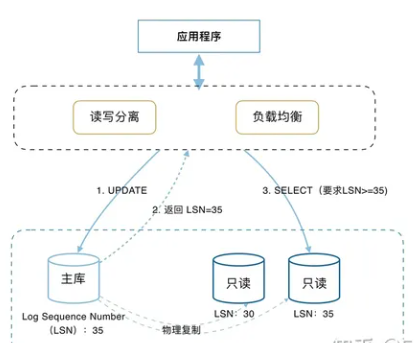
一写多读
PolarDB采用分布式集群架构,一个集群版集群包含一个主节点和最多15个只读节点(至少一个,用于保障高可用)。主节点处理读写请求,只读节点仅处理读请求。主节点和只读节点之间采用Active-Active的Failover方式,提供数据库的高可用服务。
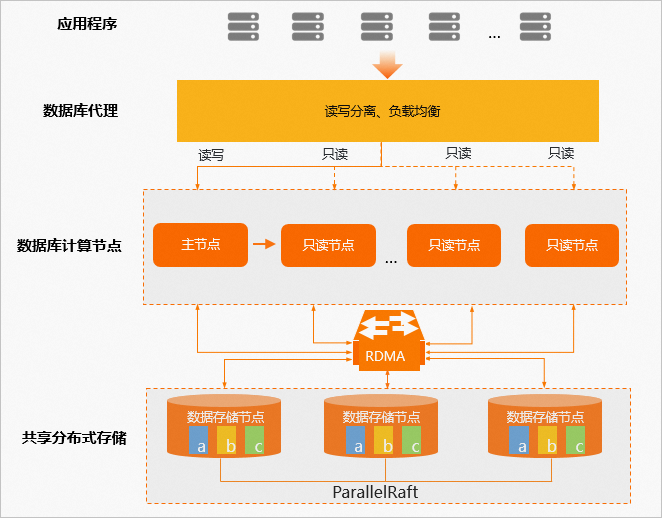
计算与存储分离
PolarDB采用计算与存储分离的设计理念,满足公共云计算环境下根据业务发展弹性扩展集群的刚性需求。数据库的计算节点(Database Engine Server)仅存储元数据,而将数据文件、Redo Log等存储于远端的存储节点(Database Storage Server)。各计算节点之间仅需同步Redo Log相关的元数据信息,极大降低了主节点和只读节点间的复制延迟,而且在主节点故障时,只读节点可以快速切换为主节点。
在 PolarDB 中,Redo Log 是用于保证数据库事务的持久性和恢复能力的重要组件。PolarDB 的 Redo Log 采用了主从架构,并通过使用共享存储来实现数据的高可靠性。
具体来说,PolarDB 主库和从库之间会有一个同步机制,通过 Redo Log 的方式将主库上的写操作同步到从库上。当主库上执行一个事务时,相关的 Redo Log 记录会被写入到共享存储中。然后,从库会通过读取共享存储中的 Redo Log 来重放这些操作,以确保从库上的数据与主库保持一致。
在这个过程中,共享存储起到了关键的作用。它是主库和从库之间传输 Redo Log 的通信通道和存储介质。PolarDB 使用高可靠性的共享存储来确保数据的可靠传输和持久化存储。

PolarDB-X支持基于 redo log 的主从复制,可以将一个 PolarDB-X 实例作为主节点,将另一个实例作为从节点,通过主从复制实现数据同步。在主从复制中,主节点负责写操作,从节点负责读操作,并通过 redo log 实现数据同步。
在主从复制中,PolarDB-X 将 redo log 存储在共享存储上,以便主从节点之间可以通过共享存储来实现数据同步。具体来说,PolarDB-X 将 redo log 存储在一个名为“redo log group”的共享存储上,主节点和从节点都可以访问该共享存储,从而实现数据同步。
需要注意的是,在主从复制中,主节点和从节点需要配置相同的参数,例如用户名、密码、数据库名称、端口等。同时,您还需要确保主从节点之间的网络连接正常,以便主节点能够将 redo log 同步到从节点上。
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


