
ModelScope用vit模型训练我自己的数据集,我怎么知道这个模型需要的数据集的要有哪些字段?
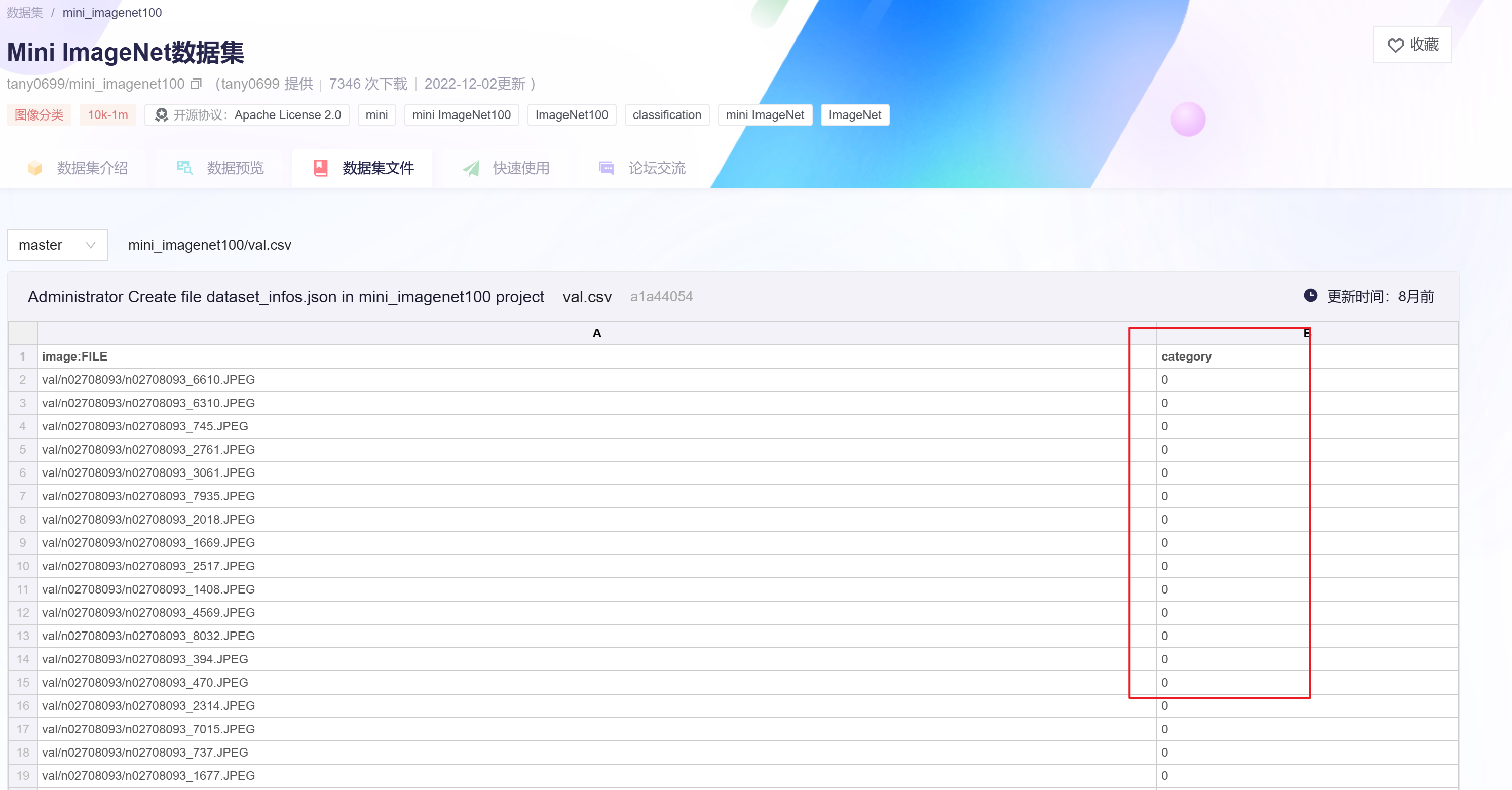
这个加载的结果大致应该是 {'image:FILE': '/to/your/path/xxx.jpg', 'category': 0}, 然后如果你需要拿到category具体名称的话,需要自行加载classname.txt的文件做映射。 不过一般模型用的话其实 0、1、2这种就行了。 具体到vit模型,需要你看一下input的格式,自己构造一下这个csv mapping文件。-此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”
当使用Vision Transformer (ViT)模型训练自己的数据集时,您需要了解模型所需的数据集字段和格式。以下是一般步骤和字段要求:
图像数据:ViT模型通常接受输入为图像数据。您需要准备一个包含训练图像的数据集。
图像尺寸:ViT模型对输入图像的尺寸有特定的要求。通常,ViT模型要求输入图像的尺寸是固定的正方形。您需要根据模型的要求,将图像调整为相同的尺寸。常见的输入尺寸包括224x224、384x384、512x512等。
数据集标注:对于监督学习任务,您需要为每个图像提供相应的标注或标签。标注可以是分类标签、目标检测框的位置和类别、图像分割掩码等,具体取决于您的任务类型。
数据集划分:为了进行训练、验证和测试,您需要将数据集划分为不同的子集。常见的划分方式包括训练集、验证集和测试集。
数据加载器:在训练过程中,您需要使用数据加载器来加载和预处理数据集。数据加载器负责从数据集中提取图像和标注,并进行必要的预处理操作,如调整图像大小、归一化等。
在使用ModelScope进行训练时,您可以参考ModelScope的文档和示例代码,了解ViT模型的输入要求和数据集的字段。通常,ModelScope提供了用于构建数据加载器和处理自定义数据集的工具和函数。您可以使用这些工具来加载您的数据集,并确保数据集字段和格式与模型的要求相匹配。
另外,根据您的具体任务和数据集类型,可能还需要进行其他特定的数据处理和准备步骤。这可能包括数据增强、数据平衡、数据集的标注格式转换等。您可以根据具体情况进行相应的数据处理操作。

