
为什么查指定字段反而慢,查*反而快了
select outstock.id
from "public"."outstock"
left outer join "public"."outstockdetail" on "public"."outstockdetail"."outstockid" = "public"."outstock"."id"
where "public"."outstock"."id" in
('50d27611abe54f848705452b3c6c6fad', '2cebeb24a42b41d2ab3650e92af397ed', '888947983b594d15b08d28bd4eb6ef3e', 'e4f601bdee564f60a033a92c0871afb6')
为什么这样outstockdetail的outstockid索引没走,select *会走, oustock是分区表

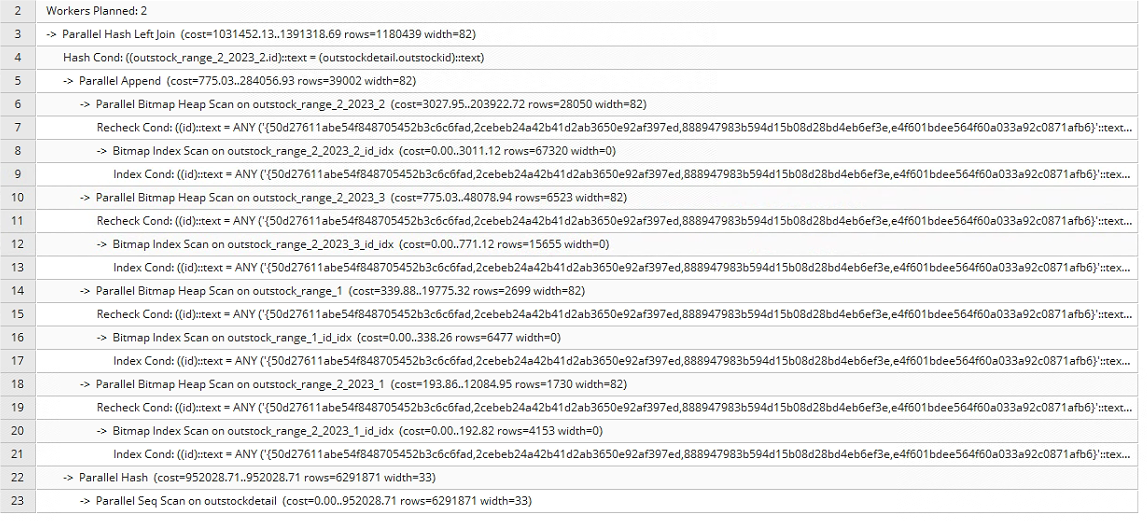
上面的是 select * 下面的是select outstock.id
应该是和分区表有关系,但同服务有其它库一样的结构,没问题,不得其解,
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在查询性能方面,查指定字段反而慢、查*反而快的情况可能与数据库的索引、表结构、数据分布等因素有关。下面是一些常见的可能原因:
索引问题:确保相关字段(如outstock.id和outstockdetail.outstockid)上有合适的索引。检查索引的选择和覆盖情况,以及索引的统计信息是否准确。
数据分布问题:确认相关数据的分布和选择性。如果查询的字段上的数据选择性较低,即有大量重复或者不唯一的值,那么使用索引可能效果不佳。
I/O开销:当查询涉及大量的列时,查询的I/O开销可能会增加,因为需要读取更多的数据页。而使用*查询可以避免不必要的I/O开销。
评估优化器的选择:优化器在执行查询计划时会根据统计信息和成本模型做出选择,可能会有不同的选择导致不同的查询性能。您可以尝试强制使用特定的索引或优化查询语句,以控制查询计划的选择。
建议您进行进一步的性能调优和分析,请考虑以下步骤:
使用数据库性能分析工具分析慢查询,确定具体的瓶颈和优化方向。
检查表的索引、索引类型和索引覆盖情况,确保相关字段上的索引是正确的并被优化器使用。
分析查询计划和执行计划,确认查询是否走了预期的路径。
更新统计信息:如果索引的统计信息不准确,可以尝试更新或重新收集统计信息。
考虑调整查询语句的写法,使用JOIN、子查询或EXISTS等不同的写法来优化查询。
虽然从直觉上看,查询更少的列(如SELECT outstock.id)应该比查询所有的列(如SELECT *)要快,但实际上并不总是这样。查询的具体内容(包括需要查询的列和连接的方式等)都会影响查询的执行速度。在某些情况下,查询所有的列可能因为能更有效地利用索引或内存等资源,而比查询部分列更快。
这个情况可能与查询的字段、表的索引和数据分布有关。以下是可能导致指定字段查询慢、而使用SELECT *查询较快的一些常见原因:
索引问题:首先要确保 "outstockdetail" 表中的 "outstockid" 字段上存在适当的索引。如果没有正确的索引,查询可能会变得缓慢。可以通过检查数据库表定义和索引设置来确认索引是否存在以及是否被正确使用。
字段选择问题:在你的查询中,如果只选择了 "outstock.id" 一个字段,数据库可能需要额外的操作来获取其他字段的值,这可能导致查询变慢。而使用 SELECT * 查询会返回整行数据,不需要额外的操作。
数据分布问题:如果你的查询条件涉及到的数据在表中分布不均匀,或者相关表之间的连接方式导致某些查询条件无法有效使用索引,那么查询性能可能会受到影响。
解决此类问题的方法可能包括:
当取得数据特别多的时候,扫描索引再去查找表,反而不如直接扫描表来的快,所以有时可能select *反而快。
出现这种情况可能是由于数据库查询优化器的原因。查询优化器根据统计信息和索引信息来选择执行计划,以达到最优的查询性能。在某些情况下,查询优化器可能会根据预估的成本选择一个不同的执行计划。
当你使用SELECT *时,查询涉及到了所有字段,而不只是outstock.id字段。在这种情况下,查询优化器可能会选择使用全表扫描,因为它认为遍历整个表比使用索引更高效。这是因为使用索引需要进行额外的IO操作,而全表扫描可以在一次读取中获取所有数据。
然而,当你只查询outstock.id字段时,查询优化器可能会选择使用索引,因为它认为使用索引只需要读取少量的数据,更加高效。但是,如果查询优化器没有正确评估到分区表的特殊性,也可能导致索引未被使用。
要解决这个问题,你可以尝试以下几点:
更新统计信息:确保统计信息是最新的,可以通过运行ANALYZE TABLE命令或者自动收集统计信息的作业来更新统计信息。
强制使用索引:可以使用查询提示(query hint)来强制使用指定的索引,例如使用/*+ INDEX(table_name index_name) */来指定使用索引。
重新设计表结构:如果查询的性能问题非常严重,可以考虑重新设计表结构,优化索引和分区策略,以提高查询性能。
楼主你好,可能是因为使用了指定字段查询,在查询时需要读取更多的索引信息,导致查询变慢。而使用SELECT *查询时,查询会读取整个表的信息,相对来说比较快。同时,分区表的查询也会受到影响。您可以尝试在查询时加上outstockdetail的outstockid索引提示,或者优化索引结构以提高查询效率。
在您的查询中,当您使用select *时,可能会导致索引被正常使用,因为它可以选择使用表的索引来提取所需的数据。而当您指定了特定字段(如outstock.id)进行查询时,可能出现索引无法使用的情况。
以下是一些可能导致此问题的原因:
索引覆盖不全:如果在outstockdetail表上的索引没有包括outstockid字段,或者索引没有包括足够的列以满足查询的需要,数据库优化器可能会选择执行全表扫描而不是使用索引。确保索引包含了您查询所需的所有字段。
数据分布不均匀:如果数据在outstockdetail表中的outstockid列上的分布不均匀,例如某些值出现频率较高,而其他值出现频率较低,那么使用索引可能不会带来明显的性能优势,因为数据库优化器可能认为全表扫描更有效率。
查询计划选择:数据库优化器根据查询复杂度、数据统计信息和可用索引等因素生成查询计划。在某些情况下,优化器可能会错误地选择执行全表扫描而不是使用索引。您可以尝试使用索引提示或强制重新编译查询来影响查询计划的选择。
为了解决这个问题,您可以考虑以下步骤:
outstockdetail表上的索引包含了outstockid字段,并优化索引以提高性能。数据库索引:如果查询的字段没有被数据库索引,那么数据库必须对表中的每一行进行全表扫描,这将花费很长时间。而如果查询的是所有字段,数据库可能会使用索引来加速查询。
数据库优化器:数据库优化器会根据查询语句的方式来选择最优的执行计划。如果查询特定字段,优化器可能无法选择最优的执行计划,而查询所有字段则可能会更容易被优化器选择到最优的执行计划。
数据库表结构:如果查询的特定字段是在一个非常大的表中,那么查询可能会非常慢,因为数据库需要扫描大量的数据。而查询所有字段则可能会更容易地遍历整个表
由于您只需要查询 outstock 表的 id 字段,因此使用 select outstock.id 语句可以避免查询 outstockdetail 表的其他字段,从而提高查询效率。
然而,如果您使用了 * 通配符进行查询,就会查询 outstock 和 outstockdetail 表的所有字段,这会增加查询的数据量和查询的复杂度,从而导致查询速度变慢。
至于为什么 outstockdetail 表的 outstockid 索引没有被使用,可能有以下几个可能原因:
outstockdetail 表的 outstockid 索引未被正确创建或者未被优化。您可以使用 EXPLAIN 关键字查看查询计划,以确定索引是否被正确使用。
outstockdetail 表的数据量较大,导致查询时需要进行大量的磁盘访问和数据扫描,从而降低查询效率。
outstock 表的数据量较小,导致查询时 outstockdetail 表的索引未被使用。在这种情况下,您可以考虑调整查询计划,或者对 outstockdetail 表的索引进行优化,以提高查询效率。
你的这个SQL 撞到了至少2个PG 的内部的优化缺陷
你现在的PG 是阿里云的PolarDB-PG 吗? 上面的2个问题 我们计划今年下半年都解决掉,并且问题2 最终的效果要比你 手工添加一下更好。
你可以尝试一下 set enable_hashjoin to off; set enable_mergejoin to off; 分区表和非分区表 都走Nest loop 后, 真实性能差别应该不大, 但分区表的 nest loop 的 估计的cost 要比非分区表的高很多。
此答案来自钉钉群“PG|POLARDB技术进阶"
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


