
在实时计算Flink为啥我滑动窗口代码错误?因为是双流join后,将这个结果输出到视图里 然后用试图去做 滑动窗口,就报错。
那我是先要把双流join后的结果输出到rds的表里,然后根据这个表再去写窗口函数 这样可以啊?INTERNAL: Occur FlinkServerException or FlinkSQLException during submitting preview: java.lang.RuntimeException: Error while applying rule StreamPhysicalWindowTableFunctionRule(in:LOGICAL,out:STREAM_PHYSICAL), args [rel#209709:FlinkLogicalTableFunctionScan.LOGICAL.any.None: 0.[NONE].[NONE ], 30000:INTERVAL SECOND, 1800000:INTERVAL MINUTE),rowType=RecordType(TIMESTAMP(3) ROWTIME RecordCreatedTime, DECIMAL(38, 2) cashflow, TIMESTAMP(3) window_start, TIMESTAMP(3) window_end, TIMESTAMP(3) ROWTIME window_time))]
at org.apache.calcite.plan.volcano.VolcanoRuleCall.onMatch(VolcanoRuleCall.java:256)
at org.apache.calcite.plan.volcano.IterativeRuleDriver.drive(IterativeRuleDriver.java:58)
at org.apache.calcite.plan.volcano.VolcanoPlanner.findBestExp(VolcanoPlanner.java:510)
at org.apache.calcite.tools.Programs$RuleSetProgram.run(Programs.java:312)
at org.apache.flink.table.planner.plan.optimize.program.FlinkVolcanoProgram.optimize(FlinkVolcanoProgram.scala:62)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram.$anonfun$optimize$1(FlinkChainedProgram.scala:59)
at scala.collection.TraversableOnce.$anonfun$foldLeft$1(TraversableOnce.scala:156)
at scala.collection.TraversableOnce.$anonfun$foldLeft$1$adapted(TraversableOnce.scala:156)
at scala.collection.Iterator.foreach(Iterator.scala:937)
at scala.collection.Iterator.foreach$(Iterator.scala:937)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1425)
at scala.collection.IterableLike.foreach(IterableLike.scala:70)
at scala.collection.IterableLike.foreach$(IterableLike.scala:69)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:156)
at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:154)
at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:104)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram.optimize(FlinkChainedProgram.scala:55)
at org.apache.flink.table.planner.plan.optimize.StreamCommonSubGraphBasedOptimizerV2.optimizeTree(StreamCommonSubGraphBasedOptimizerV2.scala:212)
at org.apache.flink.table.planner.plan.optimize.StreamCommonSubGraphBasedOptimizerV2.optimizeBlock(StreamCommonSubGraphBasedOptimizerV2.scala:157)
at org.apache.flink.table.planner.plan.optimize.StreamCommonSubGraphBasedOptimizerV2.$anonfun$doOptimize$1(StreamCommonSubGraphBasedOptimizerV2.scala:75)
at org.apache.flink.table.planner.plan.optimize.StreamCommonSubGraphBasedOptimizerV2.$anonfun$doOptimize$1$adapted(StreamCommonSubGraphBasedOptimizerV2.scala:75)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:58)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:51)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.flink.table.planner.plan.optimize.StreamC
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
一个纯流式的就是在双流Join后自己写个 UDTF 做去窗口划分的动作去模拟窗口,然后基于划分出来的窗口做 non-window agg。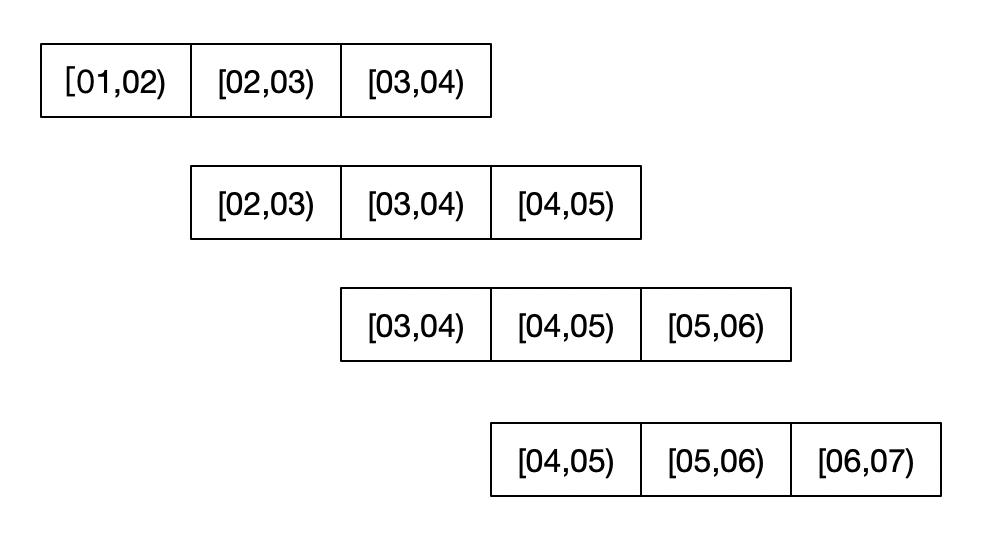 使用“group by”来模拟。如果我们把每一个滑动步长都作为一个小窗口的话,那大窗口就是连续size/slide个小窗口聚合的结果(这里先不考虑count distinct的特殊性),同时一个小窗口的需要被size/slide个不同的大窗口引用。 看上图例子,slide=1 size=3的情况下,每一个小窗口会被三个不同的大窗口引用。再深入思考,其实每个小窗口的每条记录都会被三个大窗口引用一次。所以模拟的思路就是先把每条记录扩充成3条记录,然后添加tag标识他所在的大窗口,例如在[04,05)小窗口的记录需要扩充成3条,然后3条的tag分别是02,03,04(对应大窗口的起始时间戳)。然后group by聚合的时候,聚合key额外加上这个tag,这样就可以计算出每个大窗口的聚合值。
使用“group by”来模拟。如果我们把每一个滑动步长都作为一个小窗口的话,那大窗口就是连续size/slide个小窗口聚合的结果(这里先不考虑count distinct的特殊性),同时一个小窗口的需要被size/slide个不同的大窗口引用。 看上图例子,slide=1 size=3的情况下,每一个小窗口会被三个不同的大窗口引用。再深入思考,其实每个小窗口的每条记录都会被三个大窗口引用一次。所以模拟的思路就是先把每条记录扩充成3条记录,然后添加tag标识他所在的大窗口,例如在[04,05)小窗口的记录需要扩充成3条,然后3条的tag分别是02,03,04(对应大窗口的起始时间戳)。然后group by聚合的时候,聚合key额外加上这个tag,这样就可以计算出每个大窗口的聚合值。
此回答整理自钉群“实时计算Flink产品交流群”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

