
DataWorks加工数据配置ODPS SQL节点是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,加工数据可以使用ODPS SQL节点进行配置和实现。ODPS SQL节点是一种数据加工节点,可以通过编写SQL语句对数据进行处理和转换,支持多种数据处理操作,例如数据清洗、数据转换、数据聚合等。
具体来说,您可以按照以下步骤来配置ODPS SQL节点:
在DataWorks中创建一个ODPS SQL节点。
在节点配置页面中,输入ODPS SQL语句,对数据进行处理和转换。ODPS SQL语句的编写方式和普通SQL语句类似,支持多种数据处理操作和函数,例如SELECT、JOIN、WHERE、GROUP BY、ORDER BY等。
配置节点的输入输出等参数,以便将处理后的数据输出到指定的目标表或其他节点进行进一步处理。
配置完成后,保存节点并提交作业,以便在ODPS上执行指定的SQL语句,对数据进行处理和转换。
在阿里云DataWorks中,ODPS SQL节点是用于配置并执行阿里云大数据计算服务(MaxCompute)的SQL任务的节点。ODPS(Open Data Processing Service)是阿里云提供的一种高性能、完全托管的大数据处理平台。
通过ODPS SQL节点,您可以使用SQL语言编写和执行数据加工任务。以下是配置ODPS SQL节点的步骤:
完成以上步骤后,您可以在DataWorks中成功配置ODPS SQL节点,并根据需要执行SQL任务进行数据加工操作。
请注意,在配置ODPS SQL节点时,您需要确保具备对应的ODPS(MaxCompute)服务的使用权限和资源。同时,您还需要熟悉SQL语言以编写正确的数据加工逻辑。
配置数据清洗节点。双击数据清洗节点,进入节点配置页面。编写处理逻辑。
SQL逻辑如下所示。INSERT OVERWRITE TABLE clean_trend_data PARTITION(dt=unknown)SELECT uid,trendFROM trend_dataWHERE trend IS NOT NULLAND uid != 0AND dt = unknown;INSERT OVERWRITE TABLE clean_steal_flag_data PARTITION(ds=unknown)SELECT uid,flagFROM steal_flag_dataWHERE uid != 0AND ds = unknown;INSERT OVERWRITE TABLE clean_indicators_data PARTITION(ds=unknown)SELECT uid,xiansun,warnindicatorFROM indicators_dataWHERE uid != 0AND ds = unknown;单击工具栏中的
图标。配置数据汇聚节点。双击数据汇聚节点,进入节点配置页面。编写处理逻辑。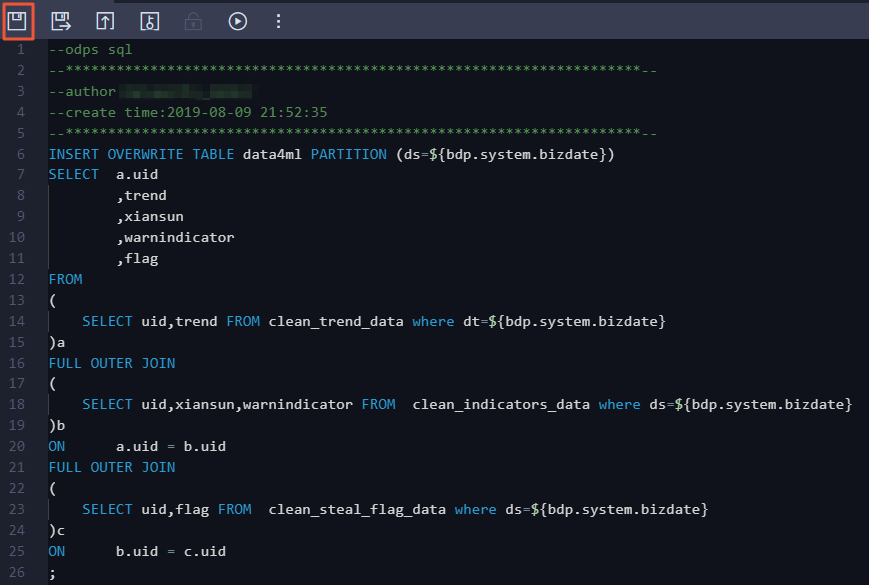
SQL逻辑如下所示。INSERT OVERWRITE TABLE data4ml PARTITION (ds=unknown)SELECT a.uid,trend,xiansun,warnindicator,flagFROM(SELECT uid,trend FROM clean_trend
https://help.aliyun.com/document_detail/146700.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


