
Flink CDC中关于维表join,假如我的动态表是A,我要补充的数据在表C,但是两者需要通过表B才能关联起来,这种情况下flinksql咋写呢 ?lookup join。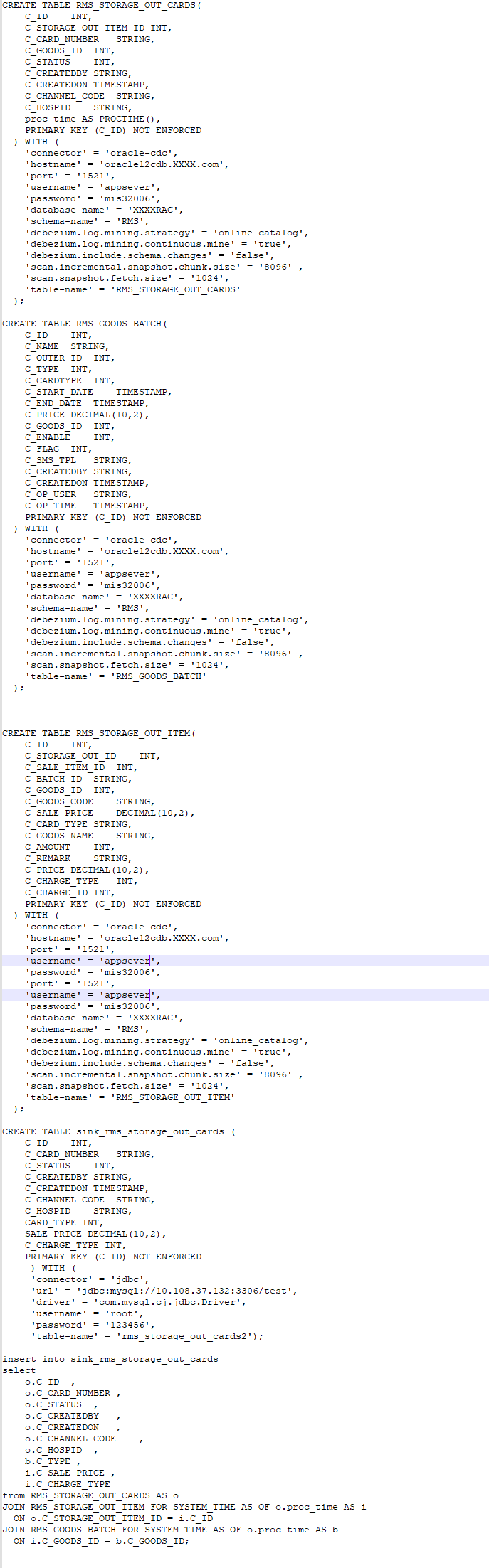
动态表A,要取的补充字段在表C,表A和表C需要表B才能关联上,这种属于多流join?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink CDC 中,使用 Flink SQL 进行维表 join 是非常方便和直观的。下面是一个示例的 Flink SQL 查询语句,展示了如何进行维表 join:
SELECT t1.*, t2.column_name
FROM table1 AS t1
LEFT JOIN table2 FOR SYSTEM_TIME AS OF t1.proctime AS t2
ON t1.key = t2.key
上述查询中,假设 table1 和 table2 分别是你的主表和维表。通过 FOR SYSTEM_TIME AS OF 子句,我们可以指定在主表的处理时间(t1.proctime)范围内从维表获取数据。key 是主表和维表之间的关联字段。
这个查询将返回主表 table1 的所有列以及维表 table2 的 column_name 列。如果某条主表记录在维表中找不到匹配的记录,对应的 column_name 值将为 null。
请根据你的实际情况进行相应的调整:
table1 和 table2 替换为你的实际表名。ON 子句)。这个示例只是一个简单的维表 join 查询,你可以根据具体的业务需求进行更复杂的查询和转换操作。
确保正确配置 Flink CDC 连接器,并在 Flink SQL 中注册所需的表后,你可以使用类似上述示例的 Flink SQL 查询语句来进行维表 join 操作。
骤进行操作:
定义 A 表和 C 表的 Schema:首先需要定义 A 表和 C 表的 Schema,包括字段名、字段类型等信息。可以通过类似如下的 SQL 语句定义:
scheme
Copy
CREATE TABLE A (
id INT,
name STRING,
...
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/db',
'connector.table' = 'A',
...
);
CREATE TABLE C (
id INT,
value STRING,
...
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/db',
'connector.table' = 'C',
...
);
定义 B 表的 Schema 并注册为 Lookup Table:接下来需要定义 B 表的 Schema,并将其注册为 Lookup Table。可以通过类似如下的 SQL 语句定义:
scheme
Copy
CREATE TABLE B (
id INT,
a_id INT,
c_id INT,
...
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/db',
'connector.table' = 'B',
...
);
CREATE TABLE Lookup_B (
id INT,
a_id INT,
cid INT,
...
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/db',
'connector.table' = 'B',
...
'lookup.cache.max-rows' = '1000', -- 可选配置,用于控制 Lookup Table 的缓存大小
'lookup.cache.ttl' = '10s' -- 可选配置,用于控制 Lookup Table 的缓存过期时间
);
注意,在定义 Lookup Table 时需要将其命名为 Lookup 开头,以便 Flink SQL 将其识别为 Lookup Table。
使用 Lookup Join 进行关联:最后可以使用 Lookup Join 将 A
嵌套一层 (A join B ) join C,On里面的关联条件用主键关联试试。cdc都是流的方式,i和b表你因该是jdbc维表的方式,如果用cdc的方式,三张表每张表刷数据都会引发你的计算。按照维表查询的场景,应该是o表有数据更新你才需要计算,多流join,你的数据在状态ttl内会越来越大,超过tll的数据可能丢数据,是的,i和b表你应该有jdbc维表的方式。此回答整理至钉群“Flink CDC 社区”。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


