
"问题1:Flink CDC差不多1s同步一条数据,效率很低,有没有优化方案?走的内网。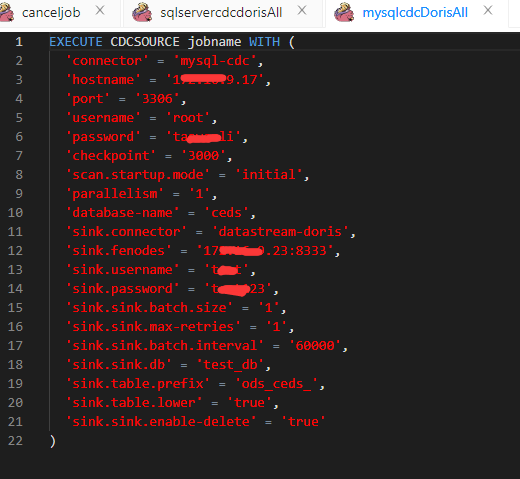
我就是dinky上弄的。
连接器版本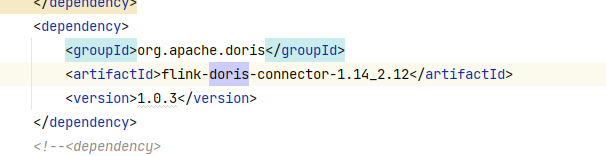
checkpoint配的3000s
问题2: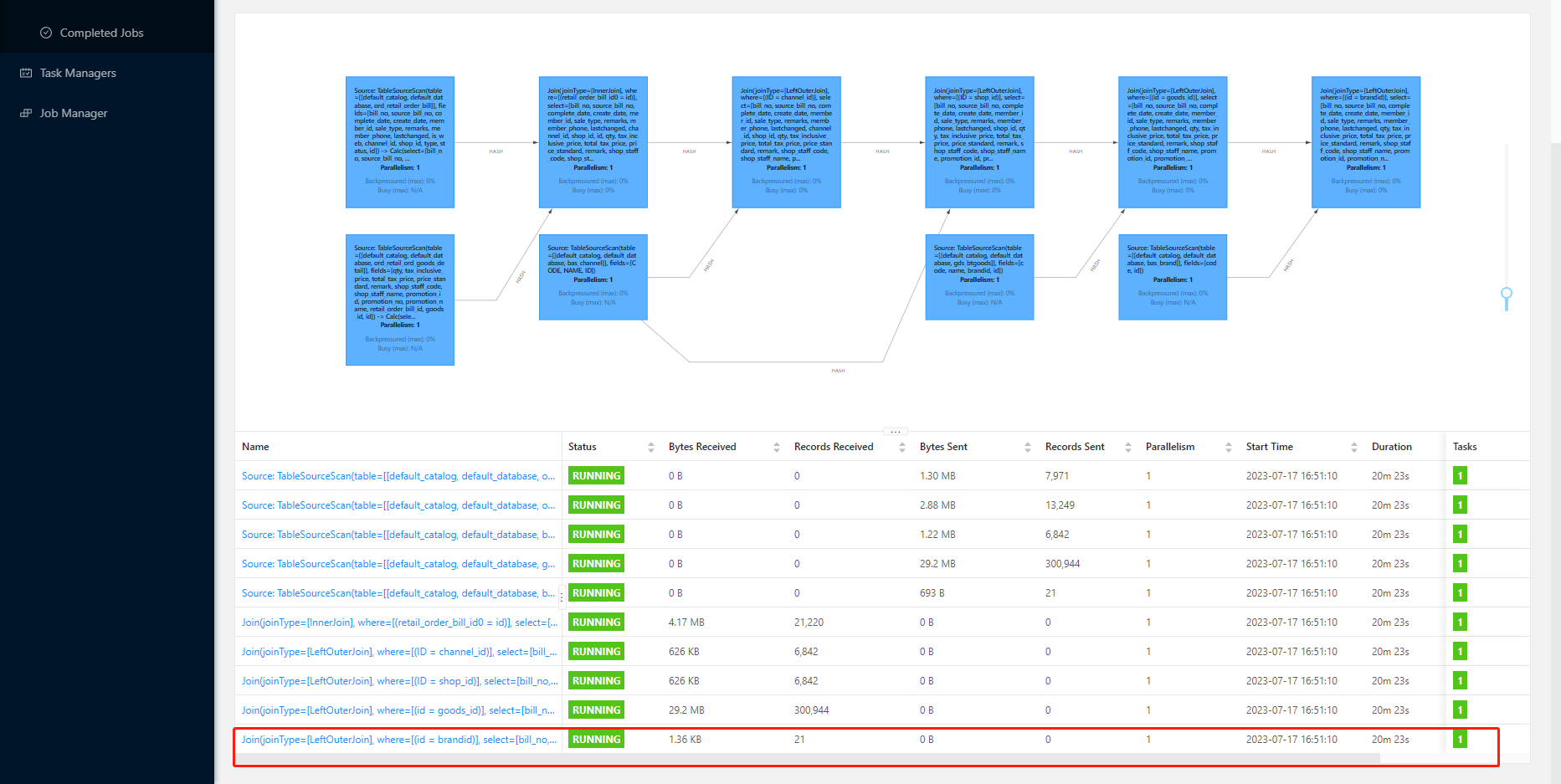
这都20分钟了,是不是有点慢了,还没有数据写进去,写到KAfka。"
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC 同步数据的效率受到多个因素的影响,例如数据源的性能、网络带宽、Flink 应用程序的配置等。如果同步效率较低,可以考虑以下一些优化方案:
增加并行度:可以尝试增加 Flink 应用程序的并行度,以提高同步效率。可以通过修改 Flink 应用程序的配置文件或者使用命令行参数来设置并行度。
调整数据源的性能:如果数据源性能较低,可能会导致同步效率低下。可以尝试优化数据源的配置,例如增加数据库连接池大小、增加硬件资源等。
使用异步 I/O:在 Flink 应用程序中,可以使用异步 I/O 来减少同步等待时间,提高效率。可以使用 Flink 提供的 Asynchronous I/O API 来实现异步读取和写入数据。
增加网络带宽:如果同步数据的网络带宽不足,可以尝试增加网络带宽,以提高数据传输速度。
调整数据格式:如果
"回答1: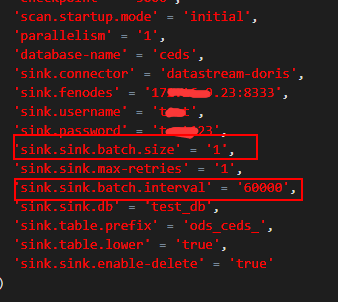
这两个参数不太合理吧,写doris是微批次的,达到flush条件才会写入,你找个batch size才1,interval 60秒。把batch size调大,interval调小。flinkcdc不可能有这么大延迟,sink参数问题。dinky是开发平台,连接器走的还是doris出的flink-connecoe-doris连接器。暂时没找到你的batch-size, 先调整下参数运行看看,flink-cdc采集数据还是很快的,主要问题都是在sink,不放心直接print对比数据时间。
回答2:你这是多流join,每个流都会触发计算,where 条件也会限制,你这个限制比较多,一个一个去了看看,先有数据,再加where 和 内连接,看是什么问题,我们一般不用inner join,很少多流join,多流join的状态是越来越大且会丢数据,看你都是cdc拉进来没必要,维表join解决。用jdbc连接mysql,再用system of 语法来,源表之需要一个cdc就行了,ord_retail_order_bill,用一个触发计算,其他从维表都可以查询到数据,都用cdc不太合适。订单表cdc进来,然后查订单明细表,档案表都是作为维表查询。此回答整理至钉群“Flink CDC 社区”"
Flink CDC 同步效率低的原因可能有很多,例如数据量过大、网络延迟、硬件性能不足等。以下是一些优化方案:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


