
问题1:请问OceanBase数据库中一个集群里有三台机器,如果对某个表进行HASH分区,分区后每个机器上都会存有这个表的全部数据,还是只存储部分1/3的数据呢?这个图中,每台机器存储了全部的数据,只是每个机器上起作用的分片不同。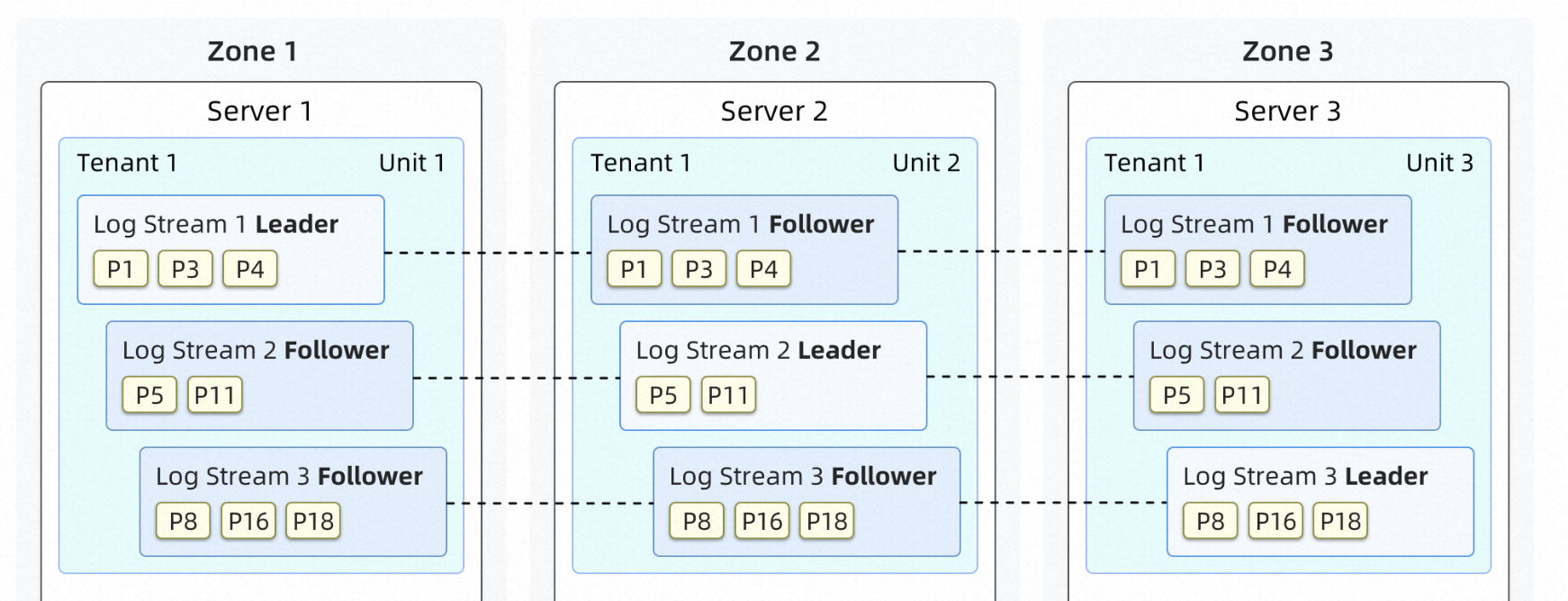
那么,当数据量非常大,一台机器存不下的时候怎么办呀?
问题2:这个是必须保证每个zone内都有表的全部数据吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在OceanBase数据库中,对于使用HASH分区的表,每个分区会被映射到某个具体的物理节点上,数据会被存储在该节点的磁盘上。对于一个集群中有三台机器的情况,假设有一个使用HASH分区的表,分为10个分区,那么每个分区会被映射到某个物理节点上,每个节点上可能会存储多个分区的数据。
具体来说,HASH分区的实现方式是根据分区键的HASH值来确定分区,将每个分区的数据存储到对应的节点上。为了实现数据的高可用和负载均衡,OceanBase使用了分布式存储和分布式事务的机制,将数据分散存储到多个节点上,同时保证数据的一致性和可靠性。在一个三节点的集群中,每个节点都会存储一部分数据,当某个节点故障时,其他节点会自动接管故障节点的数据,保证系统的高可用性和容错性。
在OceanBase数据库中,如果对一个表进行HASH分区,并且在一个拥有三台机器的集群上进行分布式存储,数据的分区和存储方式如下:
HASH分区规则:首先,通过HASH函数将表的某个列或多个列的值转换为一个哈希值。该哈希值确定了数据所属的分区。
分区分配:根据HASH函数生成的哈希值,将数据分配到不同的分区。在一个拥有三台机器的集群中,每个分区将被分配到一个特定的机器上。
数据存储:在每个分区所在的机器上,数据将以分片(Shard)的形式存储。每个分片通常包含一个或多个数据块(Data Block),这些块将数据按照一定的数据结构进行存储和管理。
副本复制:为了提高数据的可靠性和容错性,默认情况下,OceanBase数据库会将每个分区的数据进行副本复制到其他机器上。这样,即使某个机器发生故障,数据仍然可以从其他副本中恢复。
数据访问:当执行查询时,根据HASH分区规则,系统可以快速定位到具体的分区,并从相应的机器中读取数据。这样,查询可以并行地在不同的分区上执行,从而提高查询性能和吞吐量。
需要注意的是,HASH分区是根据数据的哈希值进行分配的,因此具有相同哈希值的数据将被分配到同一个分区中。这可能导致数据在不同机器之间的不均衡分布,进而影响集群的性能。为了避免此问题,可以考虑使用更复杂的分区策略,如范围分区或列表分区,以更好地控制数据在集群中的分布。
"回答1:单节点多机策略,准确说是单zone,内扩容。
https://www.oceanbase.com/docs/common-oceanbase-database-cn-10000000001697238
问题2:还得看你配置的租户是不是在每个zone内都有资源。此回答整理至钉群“[社区]技术答疑群OceanBase”。"
对于使用OceanBase数据库进行HASH分区的情况,每个机器上都会存储表的全部数据,并且每个机器上的数据是完整的。
在OceanBase数据库中,HASH分区将数据根据某个字段的哈希值进行划分,使得具有相同哈希值的数据被分配到同一个分区中。而一个分区可能被多个机器共同承担。
具体来说,在一个集群中,如果对某个表进行HASH分区,并且集群中有三台机器,那么每台机器上都会存储整个表的全部数据。不同的是,每个机器上起作用的分片不同,即它们负责处理和服务的数据分片不同。
这种方式可以提高数据的冗余性和可用性,因为即使其中一台机器发生故障,其他机器上仍然存有完整的数据,避免了数据丢失。


