
DataWorks中Maxcompute数据集成离线同步任务报错?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中进行MaxCompute数据集成离线同步任务时,可能会出现各种错误,以下是可能的原因和解决方法:
数据表或者字段不存在。在进行数据同步时,需要确保源数据表和目标数据表以及字段信息都存在且正确。如果出现数据表或者字段不存在的错误,需要检查源数据表和目标数据表中的数据表和字段是否存在,以及是否拼写错误或者大小写不匹配。
数据类型不一致。在进行数据同步时,需要确保源数据和目标数据的数据类型一致。如果出现数据类型不一致的错误,需要检查源数据和目标数据的数据类型是否一致,是否需要进行类型转换。
数据权限不足。在进行数据同步时,需要确保账号有足够的权限访问源数据和目标数据。如果出现数据权限不足的错误,需要检查账号的访问权限是否正确。
数据库连接不稳定。在进行数据同步时,需要确保数据库连接稳定。如果出现数据库连接不稳定的错误,需要检查网络连接是否正常,数据库是否可用。
当在DataWorks中执行MaxCompute数据集成离线同步任务时出现错误,可能有多种原因导致。以下是一些常见的错误和解决方法:
表结构不匹配:如果源表和目标表的结构不匹配(例如列名、列类型或分区定义不一致),会导致同步任务失败。请确保源表和目标表的结构一致,可以使用"同步表结构"功能来自动匹配表结构。
访问权限不足:如果当前账号没有足够的权限来读取源表或写入目标表,同步任务将无法执行。请确认你具有正确的访问权限,并确保账号拥有读取源表和写入目标表的权限。
资源超限:如果同步任务涉及大量数据量或计算资源需求较高,可能会超出MaxCompute的限制。检查任务设置,确保资源配额和并发数配置合理,并尝试减少数据量或优化任务逻辑。
任务依赖关系:如果同步任务的前置任务未完成或存在依赖关系错误,可能会导致同步任务失败。检查任务的依赖关系,并确保前置任务已成功运行。
数据质量问题:如果源数据存在异常或不符合预期,可能会导致同步任务失败。检查源数据的质量,并确保其满足任务要求。
如果以上方法无法解决问题,建议查看DataWorks的任务日志以获取更详细的错误信息。你可以在任务详情页或任务运行历史中查找日志,并根据具体的错误信息进行进一步排查和解决。=
数据集成的离线同步任务主要通过设置并发度,来控制任务的占用和同步速度。离线同步任务包括向导模式和脚本模式:
通过向导模式配置离线同步任务,详情请参见通过向导模式配置任务。在向导模式编辑页面的通道控制区域,您可以通过配置任务期望最大并发数来控制离线任务的并发度。通过脚本模式配置离线同步任务,详情请参见通过脚本模式配置任务。在脚本模式的编辑页面,您可以在JSON结构的配置文本中,通过JSON路径$.setting.speed.concurrent设置离线任务的并发度。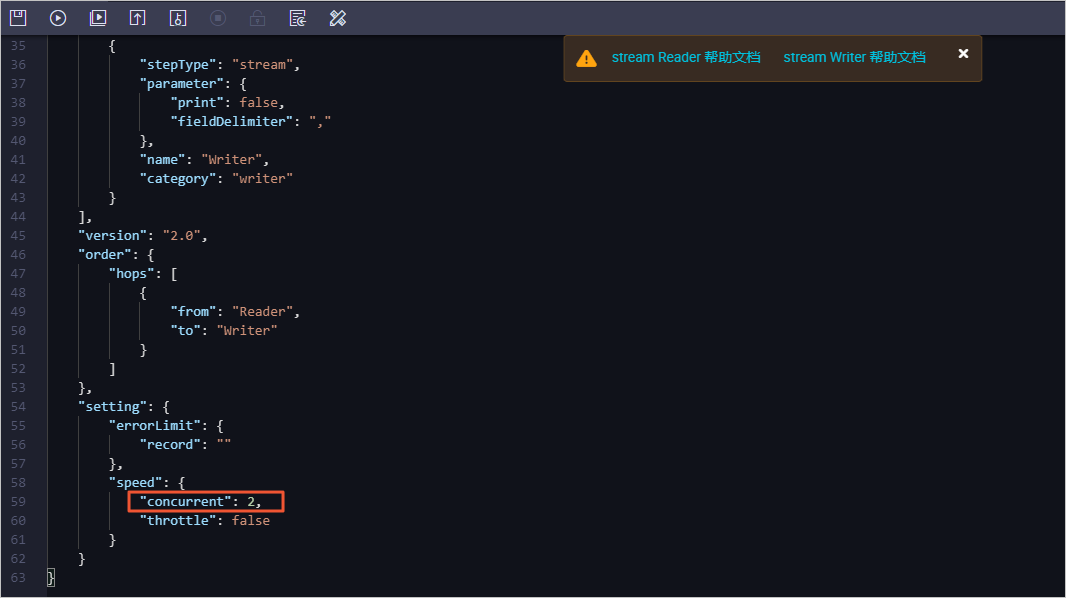
出于性能的考虑和具体数据源读取的限制,同步任务实际运行时的并发度可能小于配置的任务最大期望并发数和任务实际运行时的并发度不一致。查看任务实际运行并发度的操作如下:登录DataWorks控制台。在左侧导航栏,单击工作空间列表。选择工作空间所在地域后,单击相应工作空间后的进入运维中心。在左侧导航栏,单击周期任务运维 > 周期实例。单击相应的数据同步节点,在右侧打开DAG图。右键单击该节点,选择查看运行日志。在节点的运行日志页面,单击Detail log url链接。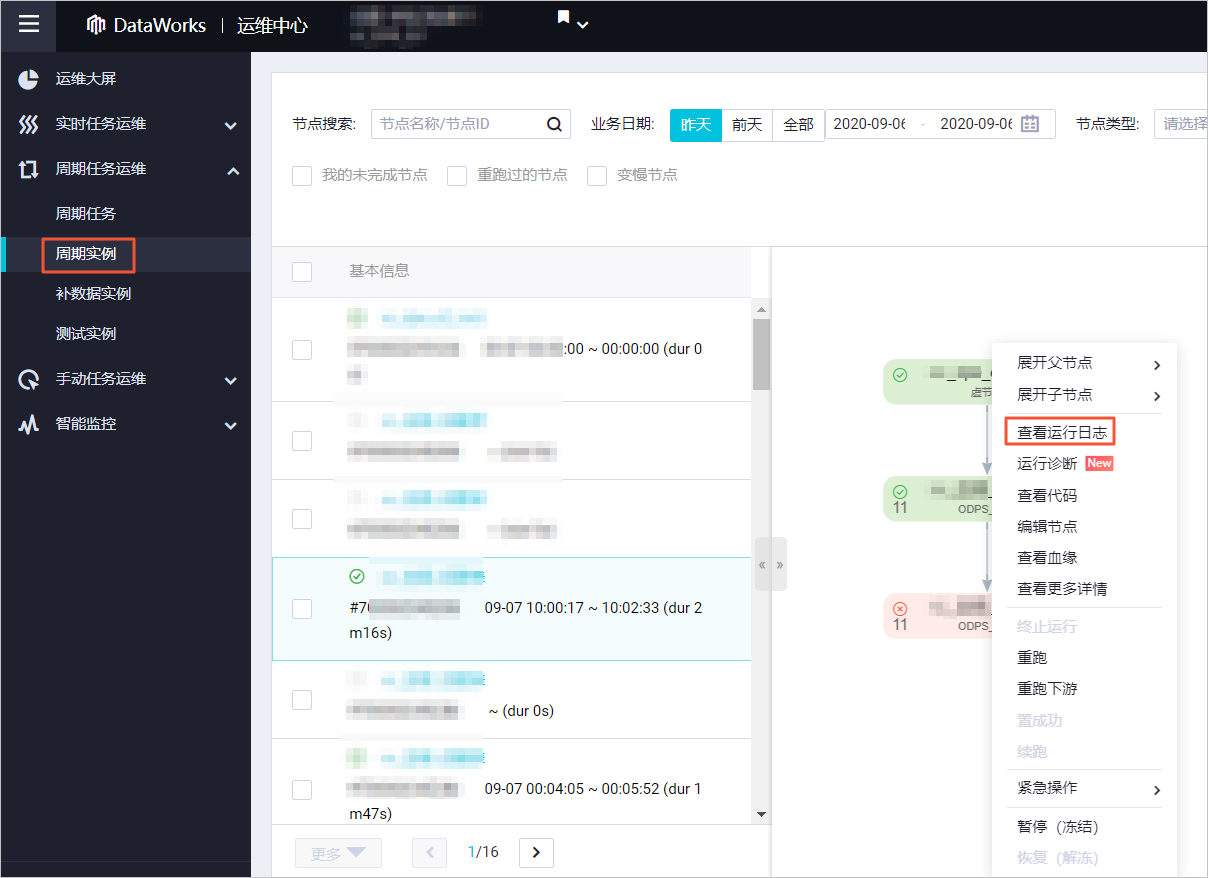
在数据同步任务的详情日志页面,查找形式为JobContainer - Job set Channel-Number to 2 channels.的日志,此处的channels即为任务实际运行的并发度。
https://help.aliyun.com/document_detail/183131.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


