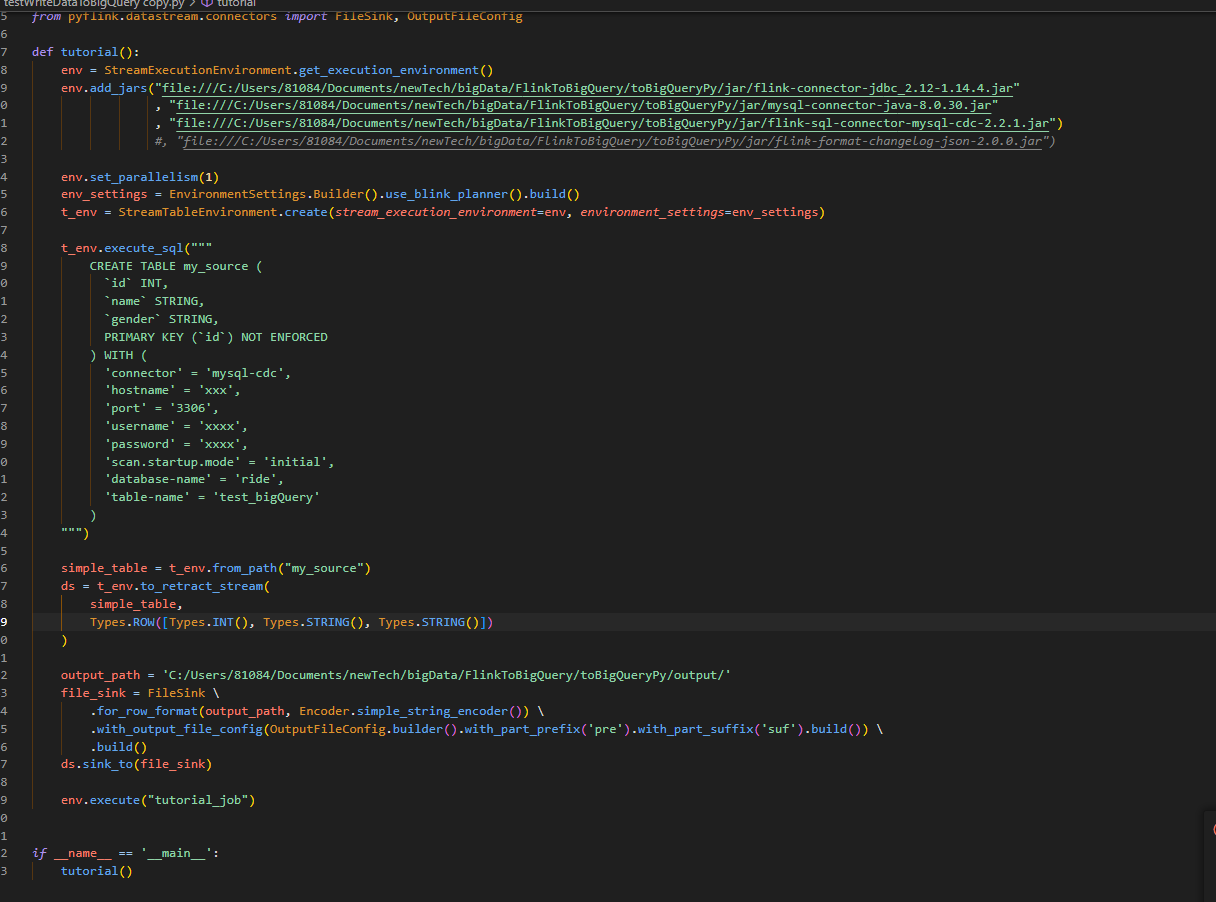
问题1:大佬们,flink CDC支持pyflink吗?我用python 3.8, flink 1.14.4,flink cdc 2.2.1时,读不到mysql binlog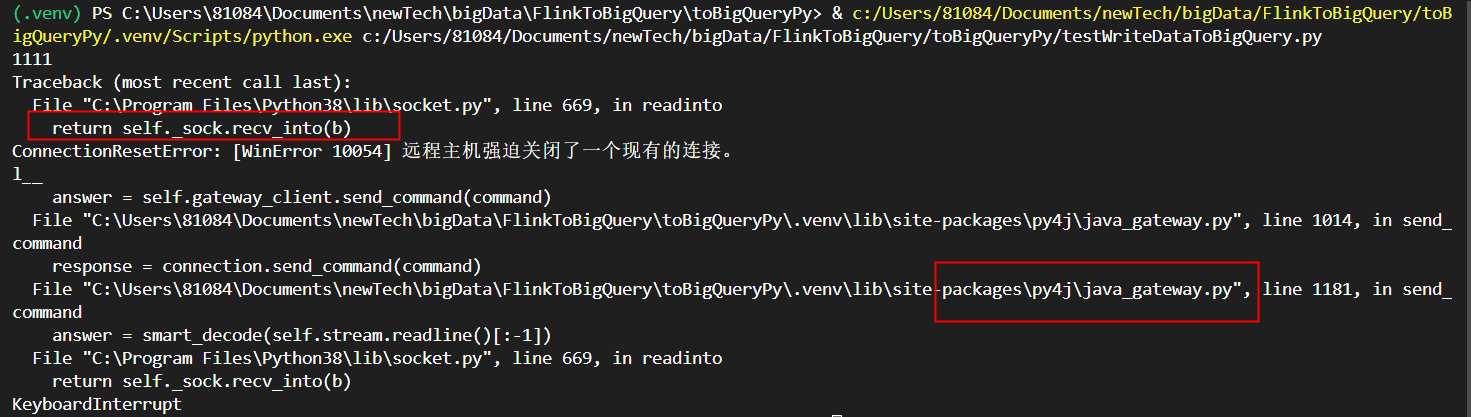
问题2:就是卡住不动,ctrl+c停止程序报这样的错误,大佬知道为啥吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是的,Flink CDC 支持 PyFlink。您可以使用 PyFlink 的 Python API 编写 Flink CDC 应用程序,并使用 Flink CDC 进行数据流的增量同步。
要在 PyFlink 中使用 Flink CDC,您需要安装 Flink CDC 的 Python 包。您可以使用以下命令来安装 Flink CDC 的 Python 包:
Copy
pip install apache-flink-cdc
安装完成后,您可以在 PyFlink 应用程序中使用 cdc_source 和 cdc_sink 两个函数来创建 Flink CDC 的数据源和数据接收器。例如:
python
Copy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import EnvironmentSettings, TableEnvironment
from pyflink.table.window import Tumble
from flinkcdc import cdc_source, cdc_sink
env_settings = EnvironmentSettings.new_instance().in_streaming_mode().use_blink_planner().build()
env = StreamExecutionEnvironment.get_execution_environment()
t_env = TableEnvironment.create(env_settings)
source_ddl = """
CREATE TABLE my_source_table (
id INT,
name STRING,
age INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = 'password',
'database-name' = 'my_database',
'table-name' = 'my_table',
'scan.incremental' = 'my_table:ts'
)
"""
source_table = t_env.sql_query(source_ddl)
source_stream = cdc_source(source_table)
sink_ddl = """
CREATE TABLE my_sink_table (
id INT,
name STRING,
age INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/my_database',
'table-name' = 'my_sink_table',
'username' = 'root',
'password' = 'password'
)
"""
sink_table = t_env.sql_query(sink_ddl)
sink_stream = cdc_sink(sink_table)
source_stream \
.key_by(lambda row: row.id) \
.window(Tumble.over("1.hour").on("ts").alias("w")) \
.apply(...) \
.add_sink(sink_stream)
env.execute("My CDC Job")
在上述示例中,cdc_source 和 cdc_sink 函数分别用于创建 Flink CDC 的数据源和数据接收器。
Flink CDC 目前不直接支持 PyFlink(Python 版本的 Flink)。Flink CDC 是基于 Java 编写的,主要用于在 Flink 的 Java 和 Scala API 中实现 Change Data Capture 功能。
然而,您仍然可以在 PyFlink 环境中使用 Flink CDC。一种常见的做法是使用 PyFlink 的 Table API 或 DataStream API 与 Java 或 Scala 的 Flink CDC 进行集成。
具体而言,您可以使用 Java 或 Scala 开发一个 Flink CDC 应用程序,将变更数据发送到 Kafka、RocketMQ 或其他消息队列中。然后,您可以在 PyFlink 中消费这些变更数据,并进行相应的处理和分析。
为了实现这种集成,您需要:
1. 使用 Java 或 Scala 编写 Flink CDC 应用程序,将 CDC 数据发送到消息队列。 2. 在 PyFlink 中编写相应的代码来消费消息队列中的变更数据,并使用 PyFlink 的功能进行处理和分析。
请注意,此方法涉及跨语言和跨平台的集成,需要合理配置和管理相关组件,并确保版本兼容性。另外,跨语言和跨平台的集成可能会增加一些复杂性和维护成本。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。