
您好,咨询一个文档智能问题,长文档信息抽取,我看对数据有要求,提到了是单页文档,那如果想要处理的文档是比较长的比如十几二十页的文档,这个是否可以处理?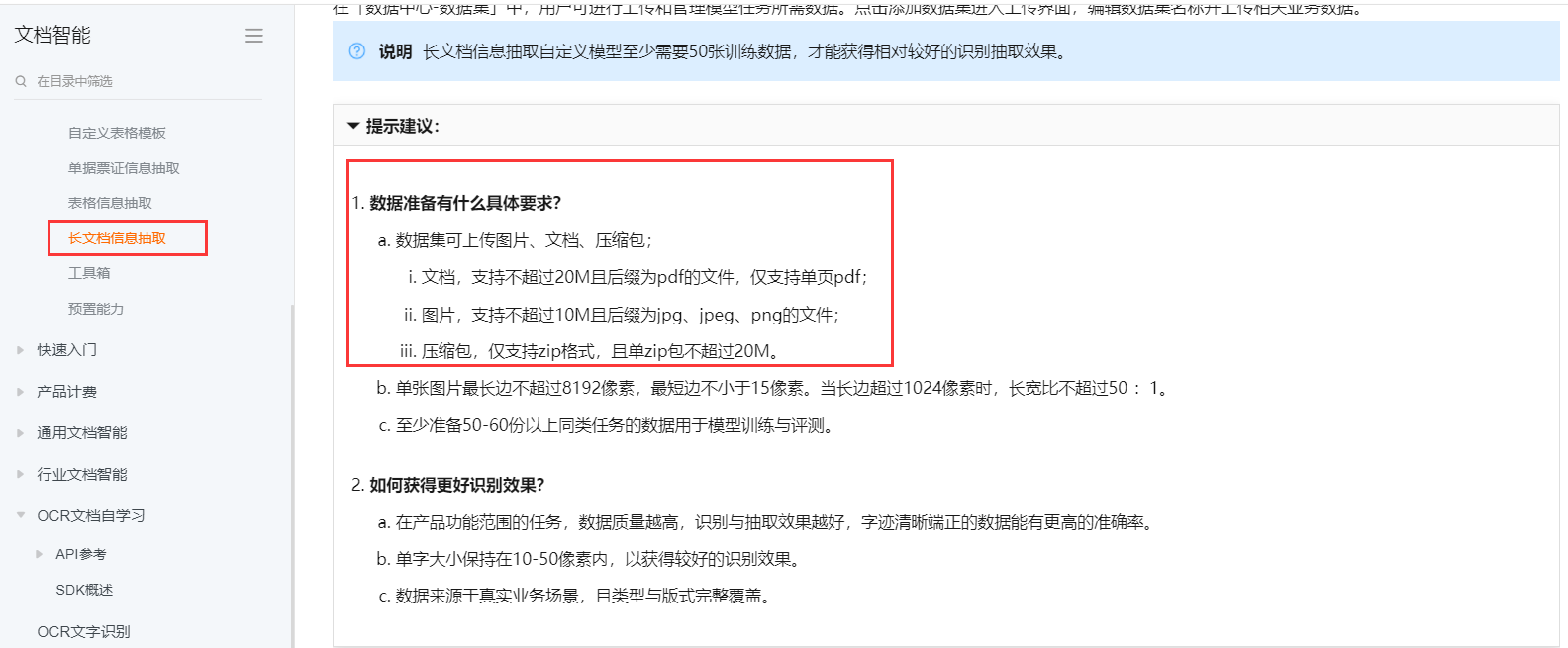
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
文档智能API通常支持处理长文档,包括多页PDF、Word文档等。不过,需要根据具体的API和需求来确定能够处理的文档长度和类型。一般来说,长文档的处理可能需要更多的时间和计算资源,并且可能需要采用分页处理或异步处理等技术来提高处理效率和稳定性。
对于长文档信息抽取,您需要考虑以下几个因素:
API支持:您需要确认API是否支持处理长文档,以及支持的文档类型和长度范围。可以查看API的官方文档或咨询API提供商的技术支持。
分页处理:如果文档太长,可能需要将其分成多个页进行处理,以提高处理效率和稳定性。您可以使用一些PDF编辑工具或编程语言库来进行分页处理。
异步处理:如果文档处理时间较长,可能需要采用异步处理方式,即将文档上传到云端进行处理,并在处理完成后获取结果。这样可以避免长时间的等待或超时等问题。您可以查看API的官方文档或咨询API提供商的技术支持,了解异步处理的具体实现方法。
如果您想处理的文档不是单页文档,而是长文档(即多页文档),那么在进行信息抽取时可能需要采用一些额外的处理步骤。下面是一些可能有助于处理长文档的方法:
分页:将长文档分割成适当大小的页面或段落,这样可以更好地处理每个独立的部分。您可以根据文档的结构和内容来选择合适的切分方式。
目录解析:如果长文档包含目录或章节标题等结构化信息,您可以首先解析这些信息,并使用它们作为指导来定位和提取特定部分的信息。
页眉和页脚处理:长文档通常会在每一页的页眉或页脚中包含重复的信息,例如标题、作者、页码等。在信息抽取过程中,您可能需要处理这些重复信息,以避免重复提取相同的内容。
上下文关联:对于跨多个页面的信息,您可能需要考虑上下文关联。例如,某些信息可能只能通过引用或参考其他页面的内容来完整理解和提取。
段落序号:长文档中的段落通常会有序号,如1.1、1.2、2.1等。这些序号可以帮助您在信息抽取过程中正确识别和排序段落。
通过结合这些方法,您可以更好地处理长文档并进行有效的信息抽取。具体的实现方法可能会根据您使用的文档智能工具或技术而有所不同,因此建议阅读相关工具的文档或参考其他类似任务的研究来获取更多细节和指导。
您好!对于文档智能问题中的长文档信息抽取,如果要处理的文档不仅限于单页文档,您可以考虑以下几种方法:
分割文档:将长文档分割成多个单页或段落,并逐个处理。这样可以使得每个单页或段落的信息抽取更加准确和可靠。
扩展模型:使用预训练的模型,如BERT等,进行文档级别的信息抽取。这些模型在处理较长文本时可能会有一定的限制,但可以通过调整输入序列长度或使用特殊的分块技术来解决。
上下文窗口:在处理长文档时,可以采用滑动窗口的方式,使用固定大小的上下文窗口来提取信息。通过在窗口内部进行信息抽取,可以捕捉到文档中的关键信息。
结合阅读理解:利用阅读理解模型,如BERT-QA等,将文档智能问题转化为问答问题,然后从长文档中寻找答案。这种方法可以根据问题的内容直接返回相关段落或句子。
这些方法可以根据您的具体需求和数据集的特点进行选择和组合。希望以上信息对您有所帮助!如果您有任何其他问题,请随时提问。

