
Flink CDC yarn提交模式有大佬遇到这个问题吗?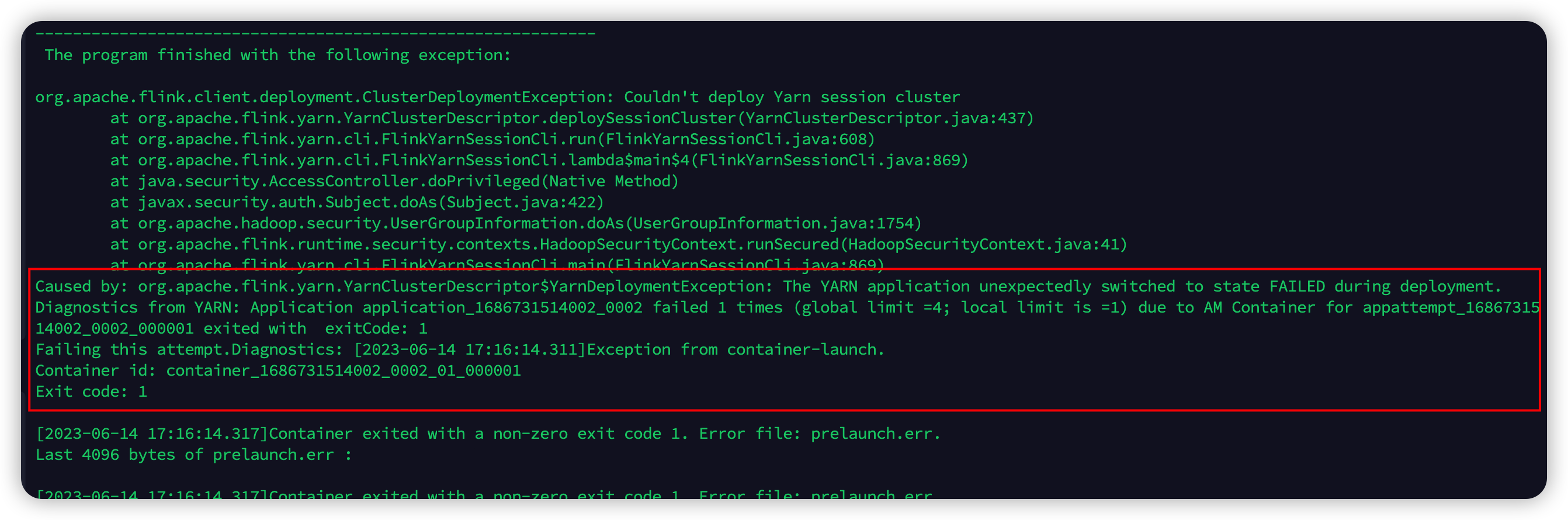
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC作业时,如果通过YARN提交模式遇到问题,可能是由于资源配置、依赖管理或提交模式选择不当等原因导致的。以下是针对该问题的详细分析和解决方案:
Flink支持三种作业提交模式:Session模式、Per-Job Cluster模式 和 Application模式。每种模式的特点如下: - Session模式:适用于较短启动时间且运行时间较短的作业。所有作业共享同一集群,但可能因资源竞争导致性能下降。 - Per-Job Cluster模式:适用于运行时间较长的作业。每次提交作业时都会启动独立的Flink集群,确保作业间资源隔离,但启动时间较长。 - Application模式:适用于包含多个作业的应用程序。每次提交应用时都会启动独立的Flink集群,减轻客户端提交作业的负担。
建议:根据您的作业需求选择合适的提交模式。如果作业需要长时间运行且对资源隔离要求较高,推荐使用 Per-Job Cluster模式 或 Application模式。
在YARN模式下,TaskManager的内存分配由YARN的资源管理器(ResourceManager)决定。即使您通过 -Dtaskmanager.memory.process.size 参数设置了TaskManager的内存大小,YARN仍会为每个容器预留额外的内存用于存储元数据和系统类库。因此,每个TaskManager对应的Container占用的内存最小为2GB。
解决方法: - 确保YARN集群有足够的资源满足Flink作业的需求。 - 如果资源不足,可以调整以下参数以优化内存分配:
taskmanager.memory.process.size: 2g
parallelism.default: 2
Flink CDC连接器的依赖管理是常见的问题来源。根据知识库资料,Flink CDC连接器分为两种类型: - flink-sql-connector-xxx:这是一个FAT JAR,包含了连接器代码及其所有依赖,适合SQL作业使用。 - flink-connector-xxx:仅包含连接器代码,不包含依赖,适合DataStream API使用。
解决方法: - 如果使用SQL作业,请确保将 flink-sql-connector-xxx.jar 放入Flink的 lib 目录中。 - 如果使用DataStream API,请手动管理依赖,并处理可能的冲突(如通过 exclude 和 shade 操作)。
在使用MySQL CDC源表时,可能会遇到以下常见问题: - Binlog格式问题:MySQL的Binlog格式必须设置为 ROW 格式,否则会导致读取失败。
SHOW VARIABLES LIKE 'binlog_format';
SET GLOBAL binlog_format = 'ROW';
server-id,否则可能导致连接冲突。SHOW VARIABLES LIKE 'expire_logs_days';
SET GLOBAL expire_logs_days = 7;
如果Flink CDC作业失败后频繁重启,可以通过修改Flink配置来调整重启策略。例如,限制最多尝试重启两次,每次重启前等待10秒:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2
restart-strategy.fixed-delay.delay: 10 s
注意:如果两次重启均失败,作业将彻底退出。
timestamp 字段时区相差8小时,可能是由于CDC作业中配置的 server-time-zone 参数与MySQL服务器时区不一致。请确保两者一致。通过以上步骤,您可以逐步排查并解决Flink CDC在YARN提交模式下的问题。如果问题仍未解决,请提供具体的错误日志或现象,以便进一步分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

