
各位大佬请问flink这个报错有遇到过吗?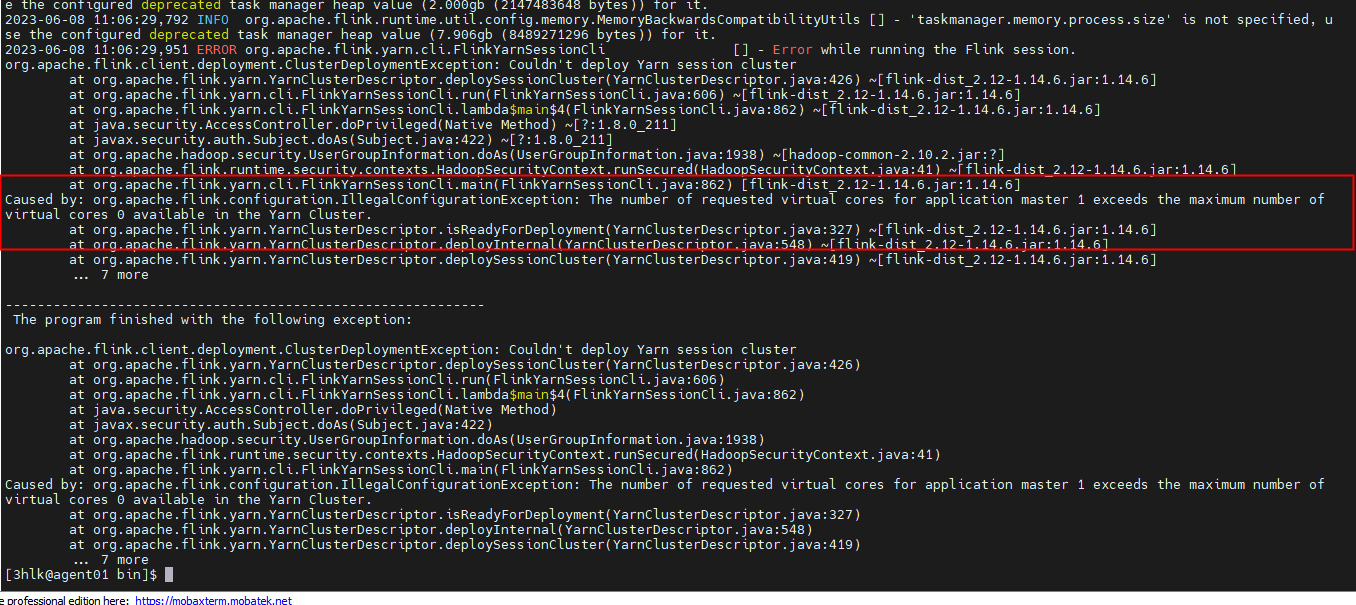 yarn-session 启动的时候报错
yarn-session 启动的时候报错
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这是一个关于YARN session启动失败的问题,具体原因是请求的应用主虚拟核心超过了最大可提供虚拟核的数量。这是由Apache Flink客户端部署ClusterDeploymentException引起的,无法部署YARN会话群集。下面是详细的异常堆栈轨迹:
Caused by org.apache.flink.configuration.IllegalConfigurationException: The number of requested virtual cores for application master 1 exceeds the maximum number of vtual cores *available in the YARN cluster*.
at org.apache.flink.yarn.YarnClusterDescriptor.isReadyForDeployment(YarnClusterDescriptor.java:327) ~[flink-yarn_2.12-1.16.6.jar:1.16.6]
at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:548) ~[flink-yarn_2.12-1.16.6.jar:1.16.6]
at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:419) ~[flink-yarn_2.12-1.16.6.jar:1.16.6]...
为了解决该问题,请参考以下可能的方法:
你遇到了 Flink YARN 容器无法部署的情况。错误提示表明,由于申请的应用主节点虚拟内核数量超过了 Yarn Cluster 可用的最大值,导致了该异常的发生。
要解决这个问题,需要考虑以下几个方面:
降低虚拟内核请求的数量: 调整 yarn.nodemanager.vmem_RESERVED 参数,减小预留给 JVM 的内存。同时,也可以增加 mapreduce.tasktracker.tasks.per.node 参数,从而允许更多的任务在单个节点上运行。
增大可用的虚拟内核数: 增加 Hadoop/YARN 集群的虚拟内核数量。可以通过修改 /etc/hadoop/yarn-site.xml 文件,在 <property> 标签下添加以下内容进行配置:
<property>
<name>yarn.scheduler.maximum-allocation.vcores</name>
<value>8</value>
</property>
<property>
<name>yarn.minimum-vcore-requirement</name>
<value>1</value>
</property>
这些更改会告诉 YARN 运行时系统应该为每个任务保留多少虚拟内核。请注意,实际使用过程中可能还需要根据实际情况微调这两个参数。
优化代码实现: 对于特定的 Flink 应用程序,可能存在一些地方没有充分利用计算能力,这时就需要分析代码逻辑,查找瓶颈点并对之进行优化。
监控集群健康状况: 监控整个 Hadoop/YARN 集群的健康情况,包括 CPU 利用率、内存占用率等指标,以便及时发现潜在问题。
强烈推荐升级至最新的 Flink 版本,因为它可能会包含已知的 bug 修复以及其他改进。此外,还可以查阅 Flink 文档 Cluster Deployment 来获取更多信息。
问题可能是由于Flink作业请求的虚拟核心数量超过了YARN集群中可用的最大虚拟核心数量。要解决这个问题,您可以尝试以下方法:
jobmanager:
rpc:
address: local
CopyCopy
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


