
不好意思打扰一下,视觉智能平台这里有个pdf一直无法识别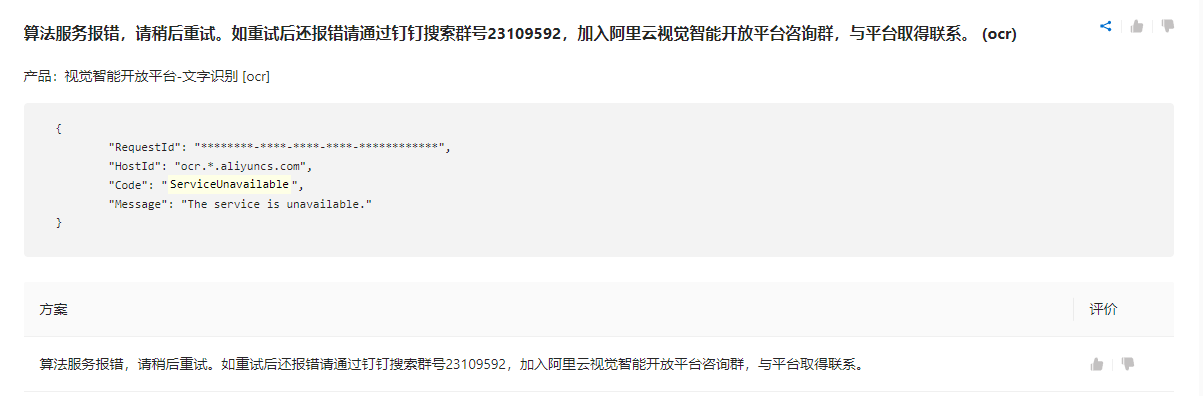
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果您在视觉智能平台使用 OCR 文字识别服务时,遇到了无法识别 PDF 文件的情况,可能是由于以下原因之一:
OCR 文字识别服务通常支持多种文件格式,如 JPG、PNG、PDF 等,但不同的服务提供商对于文件格式和要求可能会有所不同。如果您上传的 PDF 文件格式不正确或不满足 OCR 文字识别服务的要求,可能会导致识别失败或出现错误。
另外,PDF 文件的质量也可能会影响 OCR 文字识别的效果。例如,如果 PDF 文件分辨率低、文字模糊、背景噪声干扰等,可能会导致识别精度下降或无法识别。在这种情况下,建议您尝试重新扫描或转换 PDF 文件,并根据实际情况选择相应的解决方案。
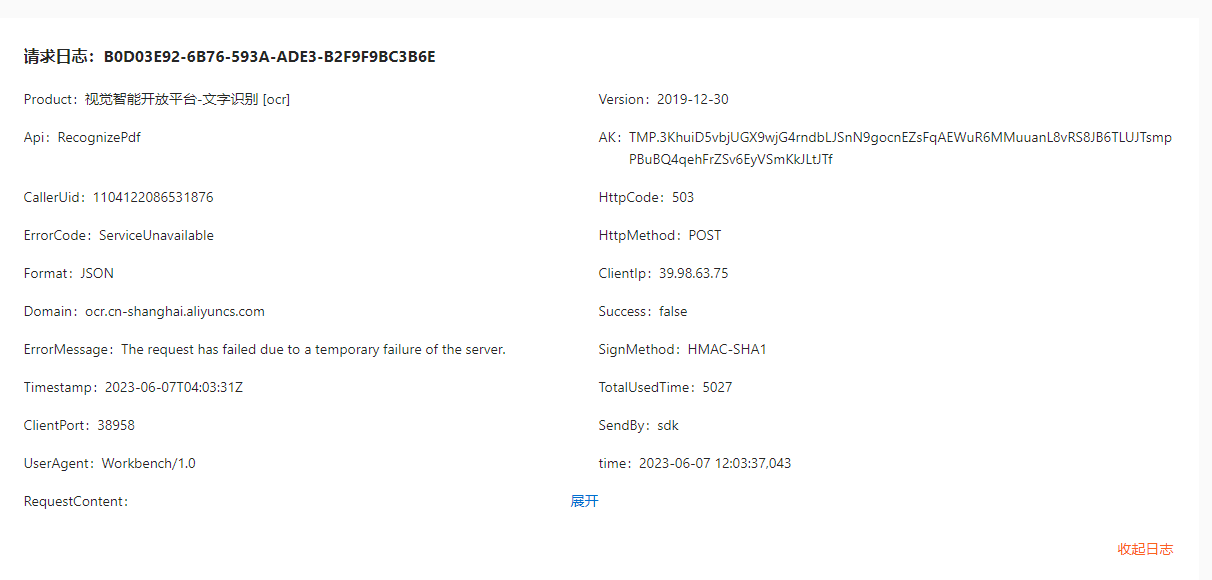
如果您遇到 OCR 文字识别服务无法识别 PDF 文件的问题,还可能是由于服务端的故障或其他问题引起的。在这种情况下,建议您联系服务提供商的技术支持人员,获取更多帮助和指导。

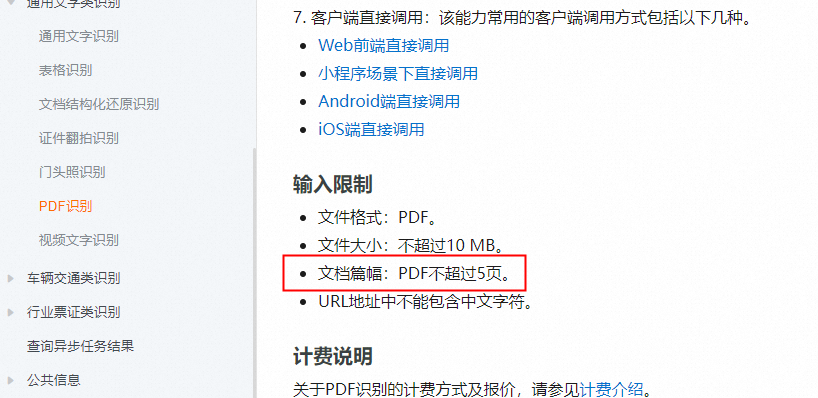 ,此回答整理自钉群“阿里云视觉智能开放平台咨询1群”
,此回答整理自钉群“阿里云视觉智能开放平台咨询1群”

