
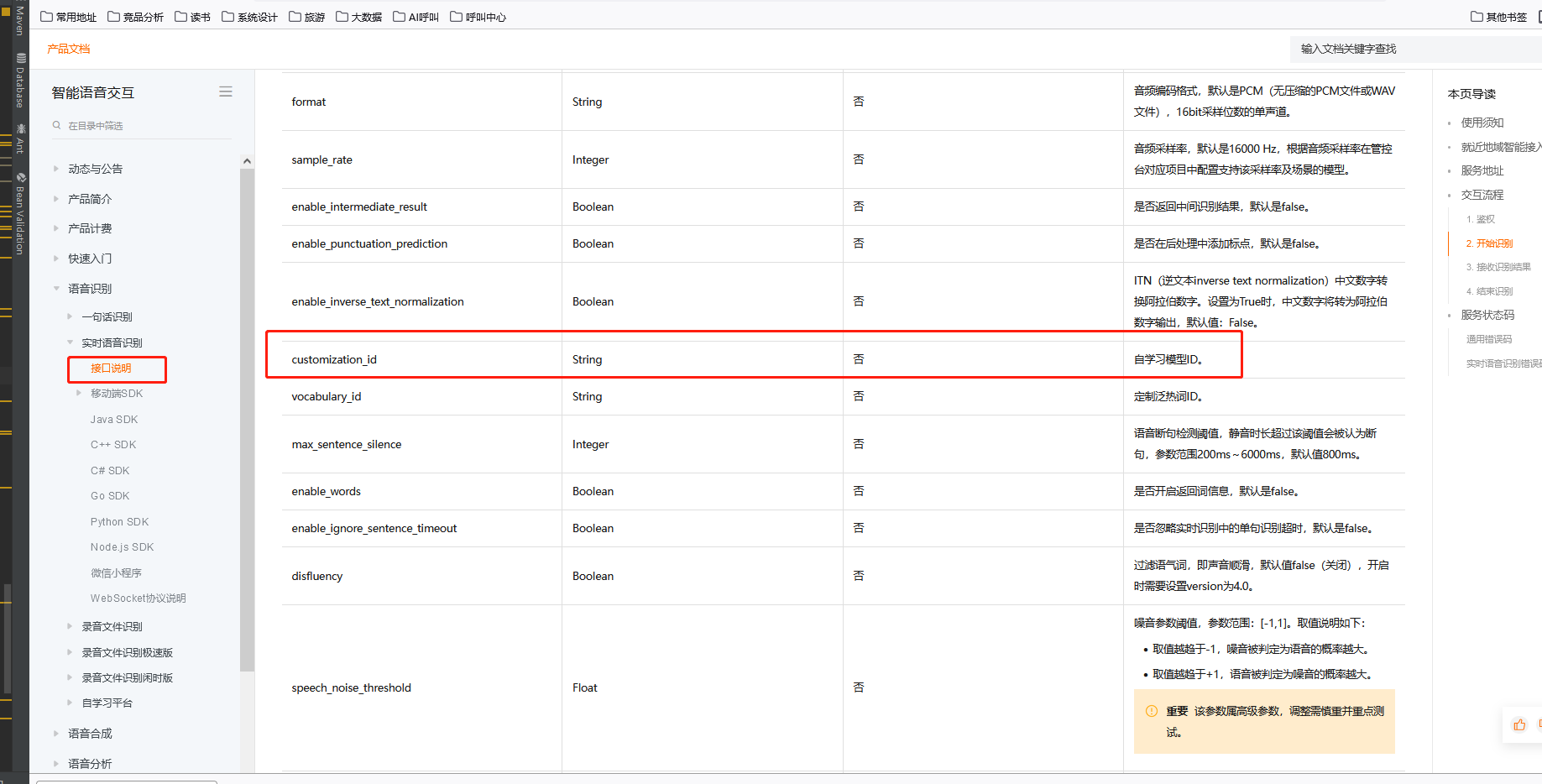
 阿里语音AI这个 顺练模型 如何进行?
阿里语音AI这个 顺练模型 如何进行?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里语音AI的顺连模型可以通过以下步骤进行:
数据准备:收集并准备用于训练和测试的音频数据集。数据集应该包含不同类型和质量的语音,以便模型可以学习不同的语音特征。
特征提取:将音频文件转换为数字信号,并提取出频谱、梅尔频率倒谱系数(MFCC)等特征。这些特征可以用于训练模型。
模型训练:使用顺连模型算法对提取的特征进行训练。顺连模型是一种序列模型,它可以学习输入信号的时间序列特征,并将其映射到输出序列。
模型调优:对训练好的模型进行调优,以提高其准确性和性能。可以使用交叉验证等技术来评估模型的性能。
测试和部署:在测试数据集上测试模型,并将其部署到实际应用中。在部署过程中,需要考虑模型的实时性能和稳定性等因素。
总的来说,顺连模型是一种比较复杂的模型,需要进行大量的数据准备和模型训练。但是,通过精细的调优和部署,可以实现高质量的语音识别和转换等应用。
是的。具体您看一下官网文档:https://help.aliyun.com/document_detail/100214.htm?spm=a2c4g.72216.0.0.15b27abfiH4n8v#topic-2572270 
此回答整理自钉群“阿里语音AI【6群】”

