
DataWorks中一键实时到maxcompute增量数据归属分区问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,将实时数据增量同步到MaxCompute时,通常需要解决增量数据所属分区的问题。这是因为在MaxCompute中,分区是按照时间范围划分的,每个分区包含一定时间范围内的数据。因此,增量数据需要被正确地分配到对应的分区中,以便后续的数据分析和处理。
为了解决这个问题,DataWorks提供了一些工具和功能,帮助您将实时数据增量同步到正确的MaxCompute分区中。以下是一些常用的方法:
使用时间字段:在您的实时数据流中,通常会有一个时间字段来记录数据的生成时间。您可以在DataWorks中配置任务时,将这个时间字段映射到MaxCompute的分区字段上,以便增量数据被正确地分配到对应的分区中。 使用任务调度:DataWorks支持任务调度功能,可以按照一定的时间间隔定时执行任务。您可以使用这个功能,将实时数据增量同步到MaxCompute的不同分区中。例如,您可以配置两个任务,一个将最近一个小时的数据同步到分区1,另一个将超过一个小时的数据同步到分区2。然后,设置两个任务的调度时间,分别为一小时和两小时。这样,您的实时数据增量就可以被正确地分配到不同的分区中。 使用ETL脚本:如果您需要更复杂的增量数据分区逻辑,可以编写ETL脚本来实现。在DataWorks中,您可以使用开源的ETL工具如Pandas等,来实现自己的数据处理逻辑。然后,将处理后的数据导入到MaxCompute中,并按照您的要求分配到不同的分区中。 总之,DataWorks提供了丰富的工具和功能来解决实时数据增量到MaxCompute的分区问题。您可以根据具体的需求和场景来选择适合的方法。
为何同步解决方案(mysql==》maxcompute)中源端mysql数据更新时间为28号,但是却出现在了maxcompute的base表的27号分区中? 现象如下图(在查询odps数据的时候发现updatetime为12.28号08:33的数据所在的maxc表分区为27号分区): 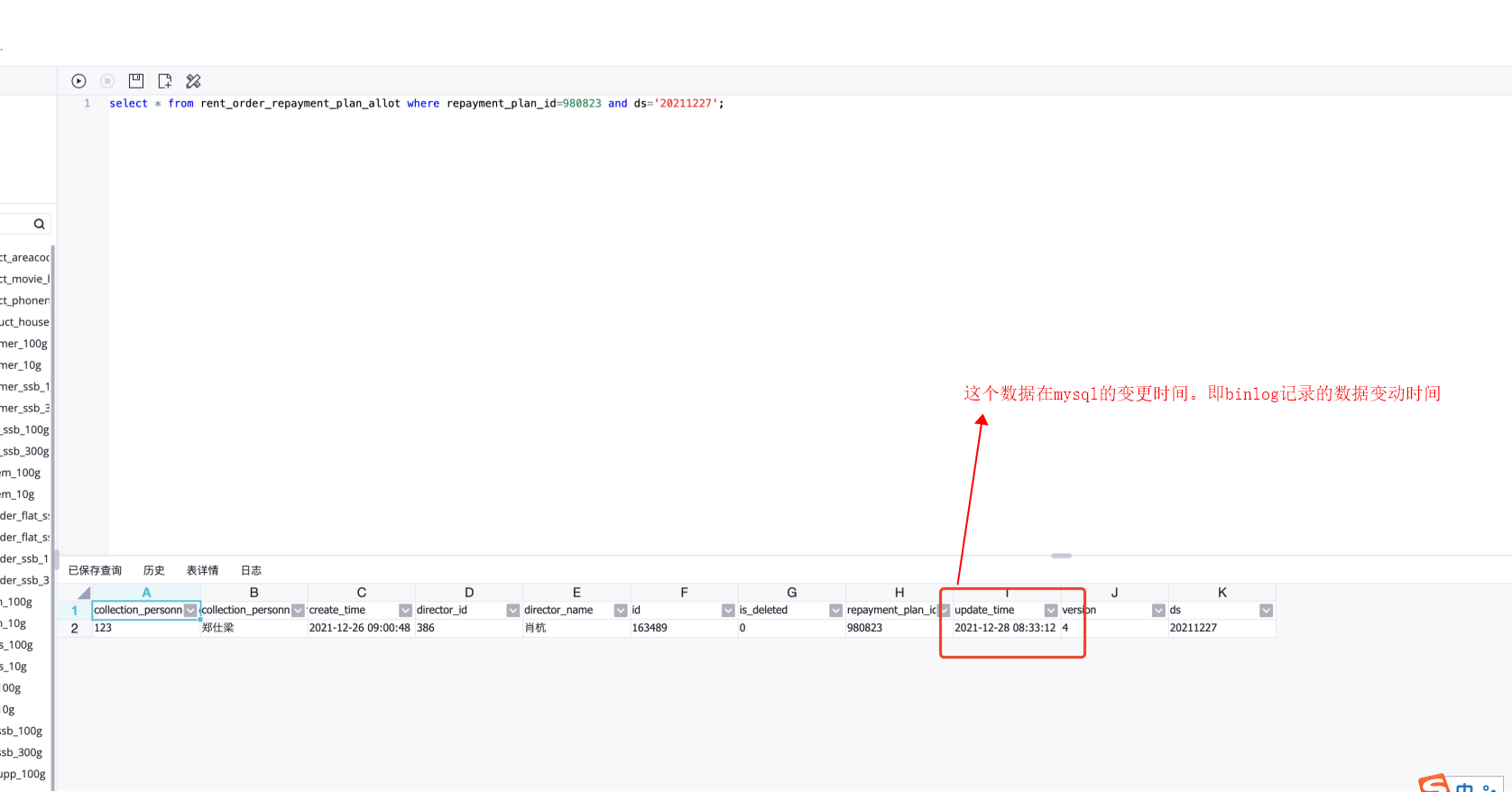
A:举例说明: 12.26号创建了一个同步解决方案(mysql一键实时同步到maxcompute)并正常提交执行。 12.28号mysql中添加了一个表,希望将该表也纳入同步解决方案中,于是对同步解决方案任务进行了修改并在此提交发布执行,修改任务配置并提交执行的时间是12-28号。 基于此情况,重新提交执行的任务会做2个部分的处理 1.离线全量部分(将 2021-12-28 17:15:01时间之前的所有的mysql历史数据全部写到odps base表的27号分区去,作历史数据) 2.实时任务部分,将2021-12-28 17:15:01时间之后的数据增量写到log表的相应的分区内。作增量数据。(排查实时同步任务日志中点位记录,见下图) 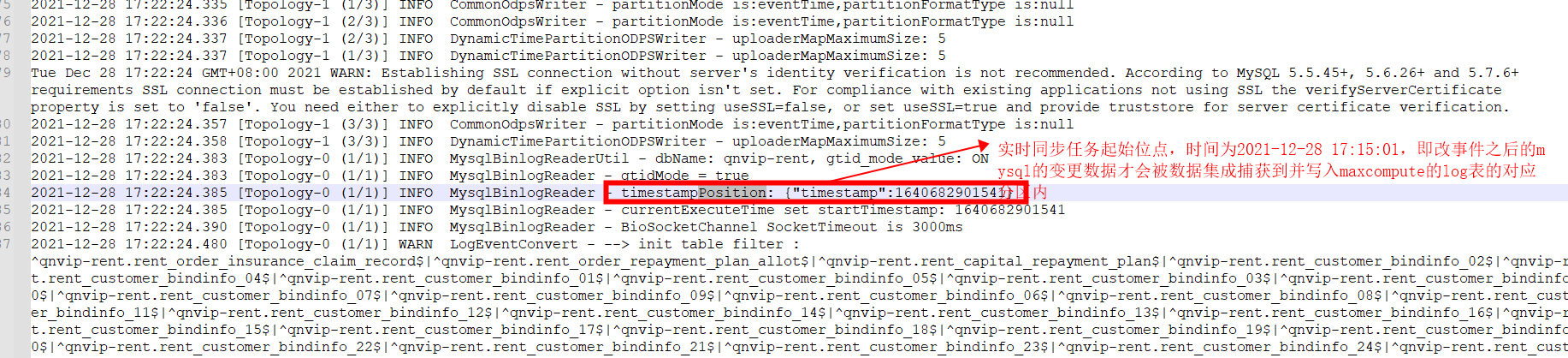
用户侧mysql中updatetime为12.28号08:33的数据不在这个实时同步任务位点时间之后,其被认定为历史数据。 如何解决:当同步解决方案希望添加或者删除某些表,实时任务启动时可充值位点为当日时间0点0分0秒,如此可将增量数据全部捕获并写入目的端maxc 的log表中,第二天log表和base表合并时会将当日分区数据归纳到当日分区中去。,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


